"Surge Protocol V3: Entity-Based AI-Search Eligibility (Daryl Osborne)"
Why most AI SEO tools guess instead of measure, and a framework of three eligibility filters plus nine dataset roles for getting cited in AI answers.
On this page
- Main takeaways
- Key points
- The unreliability thesis
- Presenter background
- Nine-year origin narrative
- Three eligibility filters
- Nine dataset roles
- Surge V3 architecture (four layers)
- Stage-prop demo (Real Geeks template site)
- Rapid-fire example queries (four roles, four citations)
- Sixty-second brand audit (three checks)
- Closing thesis and CTA
- Slides
- Source
This Day 1 session is filed under Daryl Osborne (the deck author, whose closing slide reads "I'm Daryl Osborne"). The on-stage presenter introduced himself in the recording as "Eric Lawrence," an unverified name whose relationship to Daryl Osborne is unknown and cannot be resolved from the source material. The talk argues that SEO has shifted from keyword-based optimization to entity-based AI-search eligibility, and that most current AI SEO tools are unreliable prompt wrappers that guess rather than measure. It walks through a nine-year origin story, lays out a framework of three sequential eligibility filters and nine dataset roles, demos a compute-eligibility failure on a real template site, and closes with a live sixty-second brand audit and a beta-access CTA.
Main takeaways
-
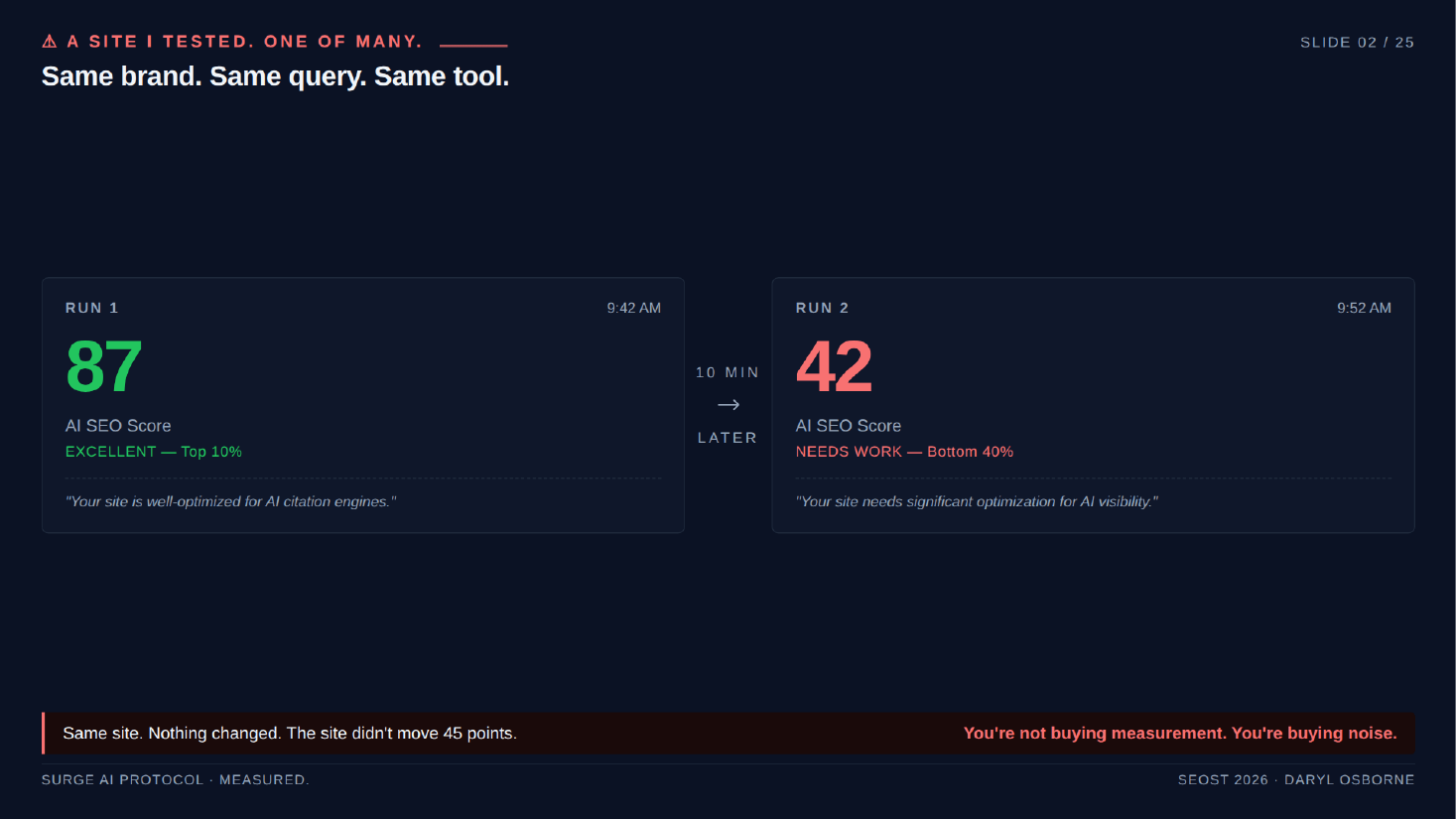
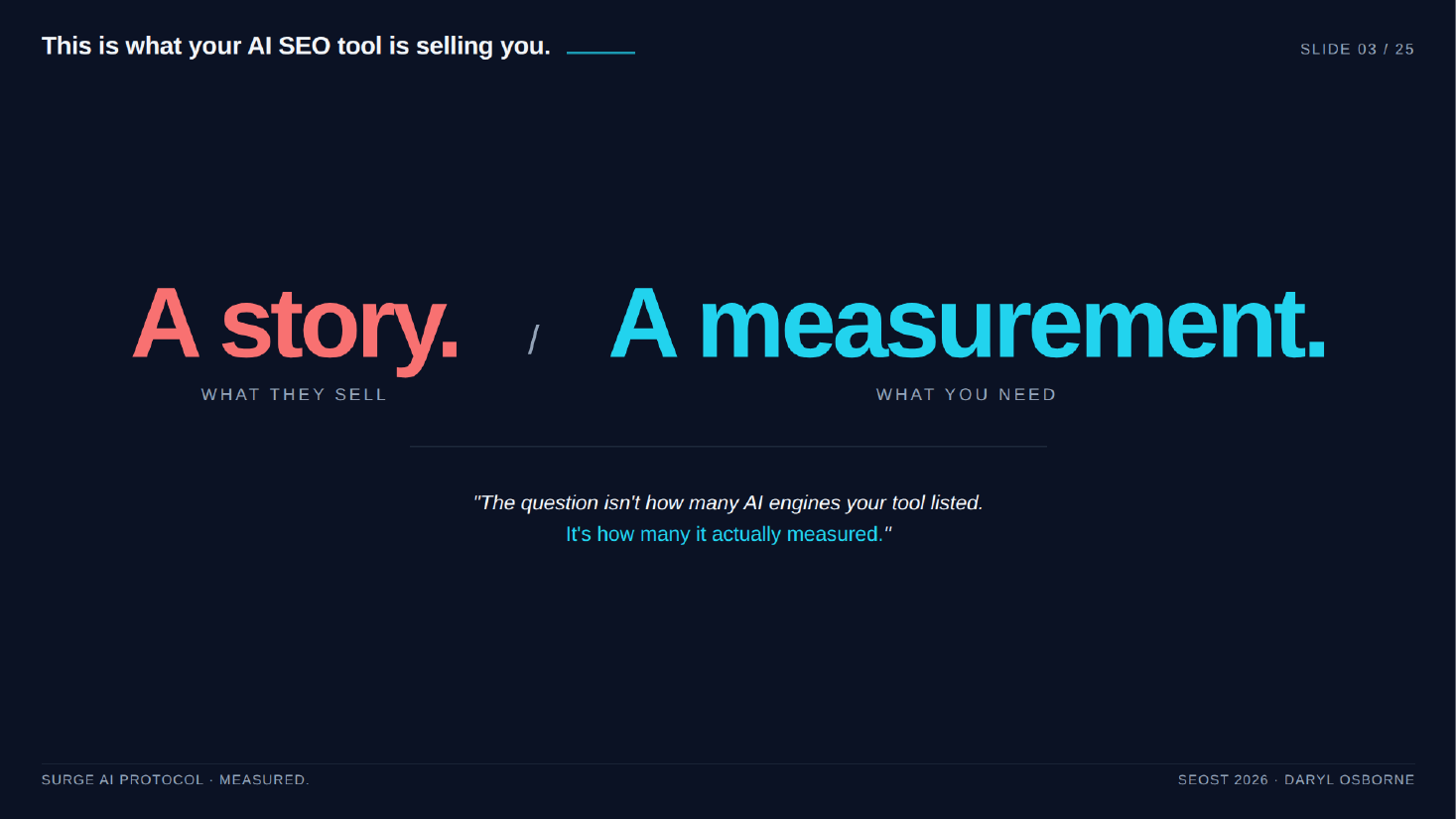
Most AI SEO tools guess rather than measure, so their scores are noise. The presenter showed one leading tool scoring the same brand 87 on run one and 42 on run two, ten minutes apart with nothing changed. He reframes the real question as not how many AI engines a tool lists, but how many it actually measured.
-
Search has moved from pages to entities, and the presenter claims to have seen it early. He read Google patents on entity recognition, dataset modeling, and topic clustering in 2014 while the industry argued about keyword density. The whole talk reframes SEO around being cited in AI answers rather than ranking in ten blue links.
-
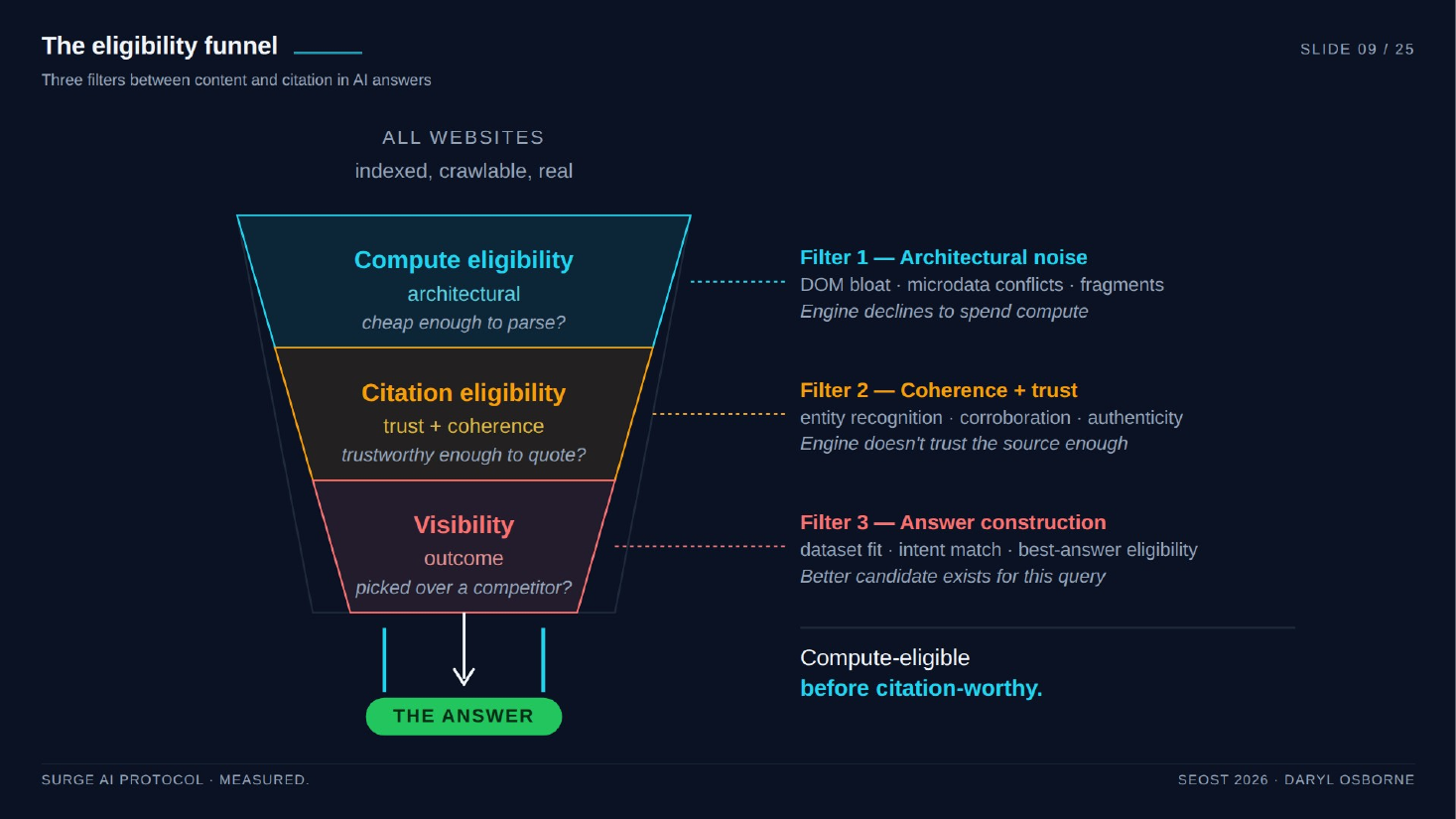
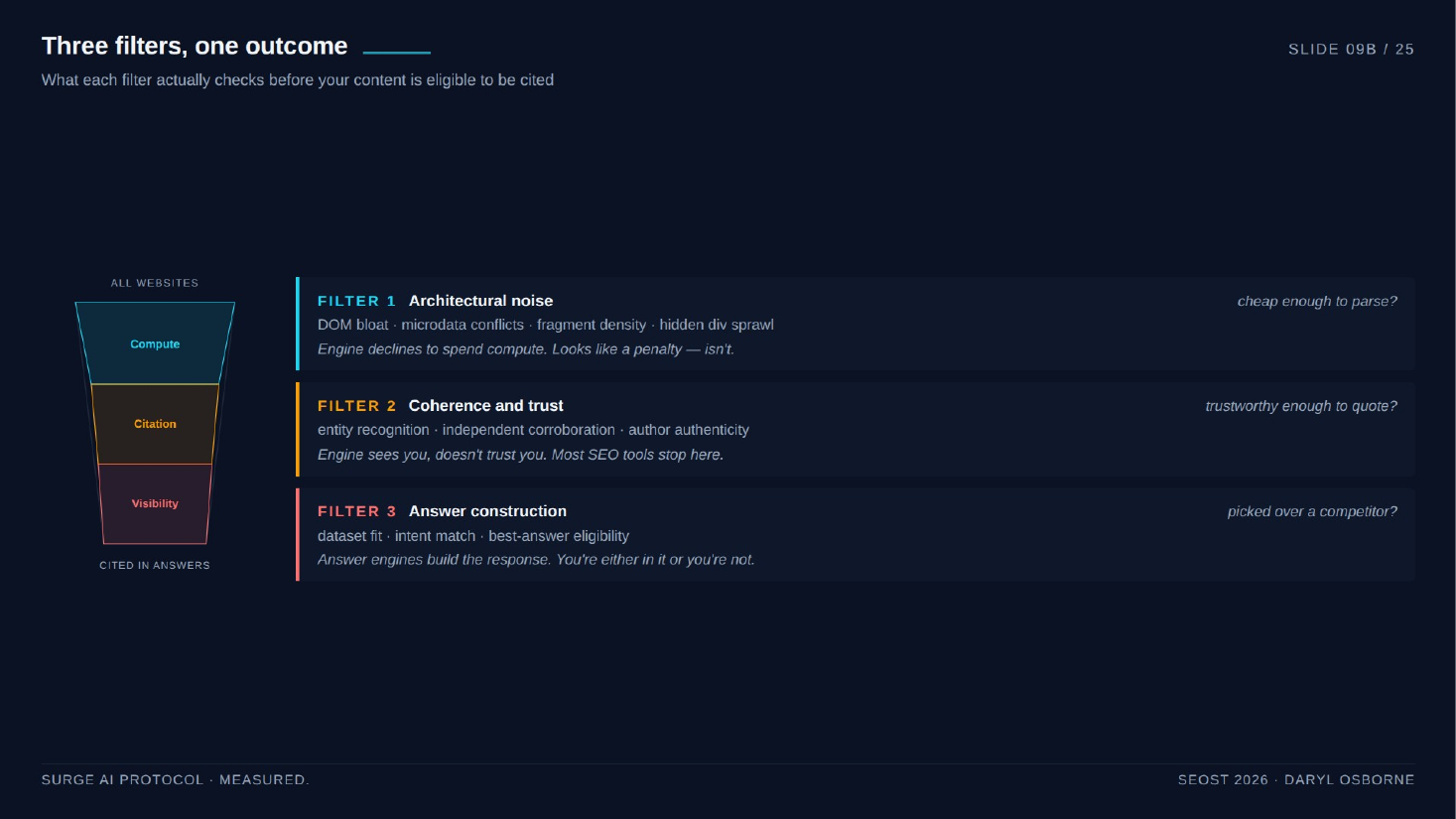
Three sequential filters gate every AI citation. Filter one is compute eligibility (is the site cheap enough to parse), filter two is citation eligibility (is the source trustworthy enough to quote), and filter three is answer construction (which eligible candidate belongs in this specific answer). He claims most tools operate only in filter two, because a prompt wrapper cannot measure filter-one issues like DOM bloat.
-
When filter one fails, the symptoms mimic a penalty. Sudden traffic drops, de-indexing, and disappearing citations often mean the engine stopped spending compute on a bloated site, not that the site was penalized. SEOs then waste time hunting in content, links, and schema.
-
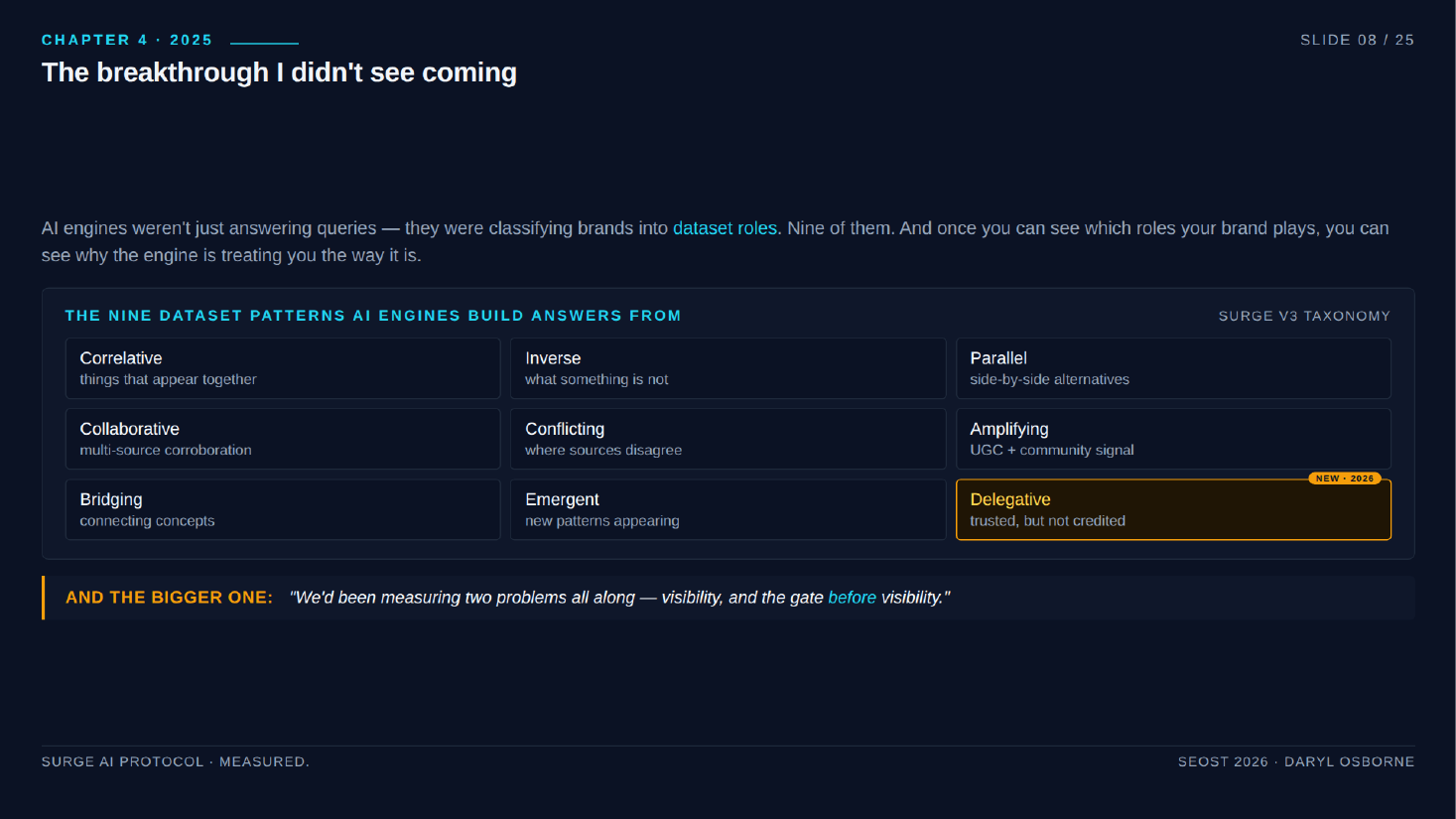
AI engines classify brands into nine dataset roles, each with a different intervention. The roles are Correlative, Inverse, Parallel, Collaborative, Conflicting, Amplifying, Bridging, Emergent, and Delegative. Knowing which role applies tells you what play to run instead of using one generic process.
-
The Delegative role explains traffic drops without citation drops. The engine uses your schema, GBP, reviews, hours, and prices to answer the question without naming you, so you are trusted infrastructure but not visible authority. The hardest intervention is converting from data source to named authority.
-
Surge is positioned on real measurement: eight data sources, twenty-plus signals. Sources include three AI citation engines (Anthropic, Perplexity, OpenAI) queried directly with API logs kept, Google NLP entity salience, real SERP / backlink / Google Business Profile data, and the live JavaScript-rendered page (via Playwright, not Puppeteer). The pitch contrasts this with tools that call ChatGPT once.
-
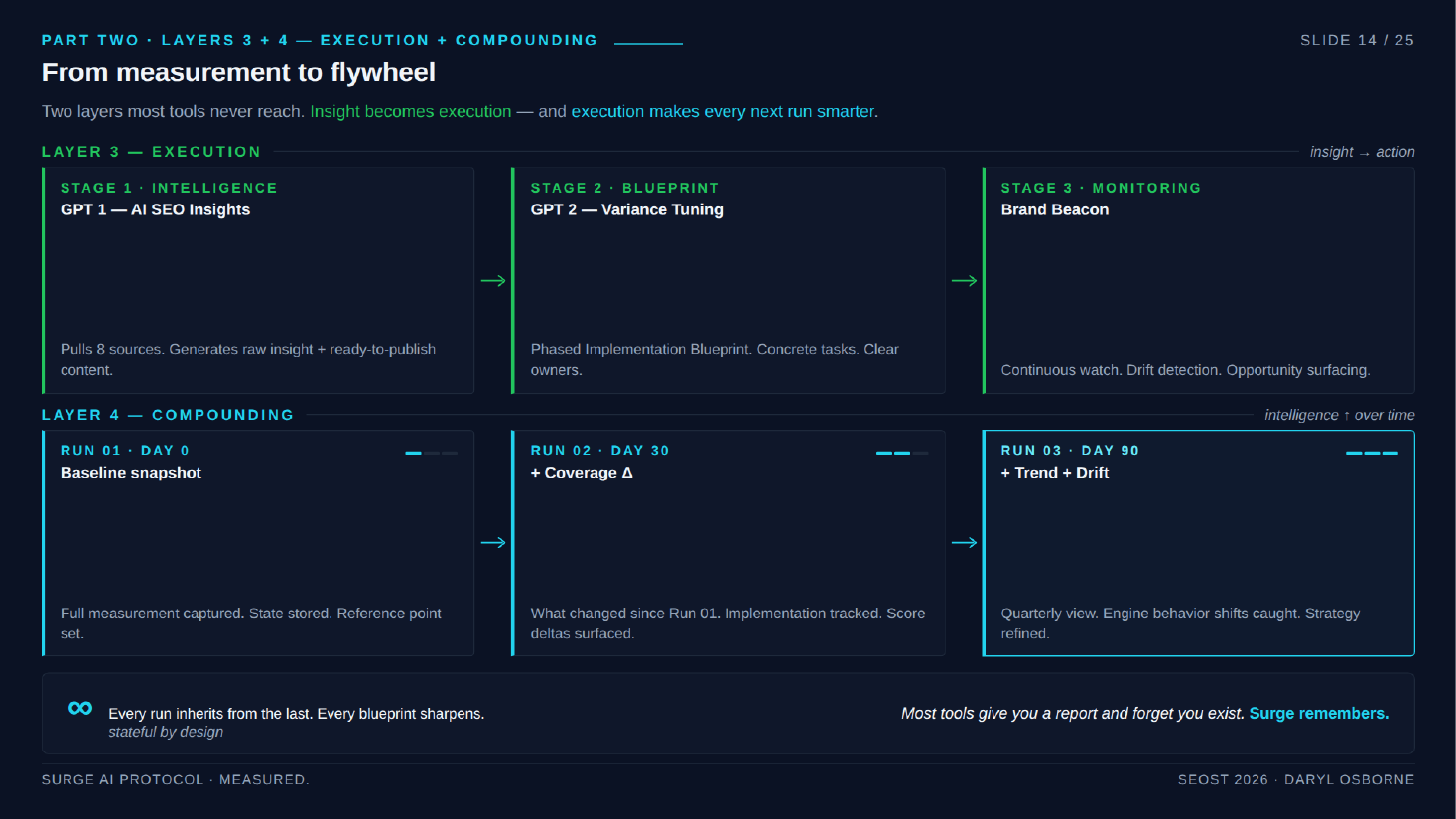
The output is a phased blueprint plus a compounding state model, not a one-off score. A two-GPT execution layer (AI SEO Insights, then Variance Tuning Companion) produces tasks and owners, while Brand Beacon monitors drift. Day 0 / day 30 / day 90 runs build a trend line so each run inherits from the last.
-
A live three-check brand audit lets the audience self-diagnose in sixty seconds. Check entity recognition in Google NLP (ORGANIZATION with salience above 0.10), citation reality in Perplexity, and corroboration count via independent third-party results for the brand name. Failing any of the three is framed as a "Surge problem."
Key points
The unreliability thesis
- A leading AI SEO tool scored the same brand, same query, same tool: run one was 87 (described as excellent, top ten percent), run two was 42 (needs work), ten minutes apart with nothing changed. A 45-point swing.
- The argument: most AI SEO tools wrap a prompt around an LLM and ask "is this site good for AI search," getting a different story every time. That is buying noise, not measurement.
- Take-home line: "The question isn't how many AI engines your tool listed. It's how many it actually measured."
Presenter background
- Says "my name is Eric Lawrence" in the recording; the deck closing slide says "I'm Daryl Osborne."
- Was an IT professional for 20-plus years before starting SEO in 2010, and left the corporate world in 2015.
- Mentions using a roughly $35 voice-activated recorder to capture conversations, transcribe them, and feed transcripts to AI to generate app ideas.
Nine-year origin narrative
- 2014: Google filed patents on entity recognition, dataset modeling, and topic clustering, which he read while the industry argued about keyword density. Lesson: search would be about entities, not pages.
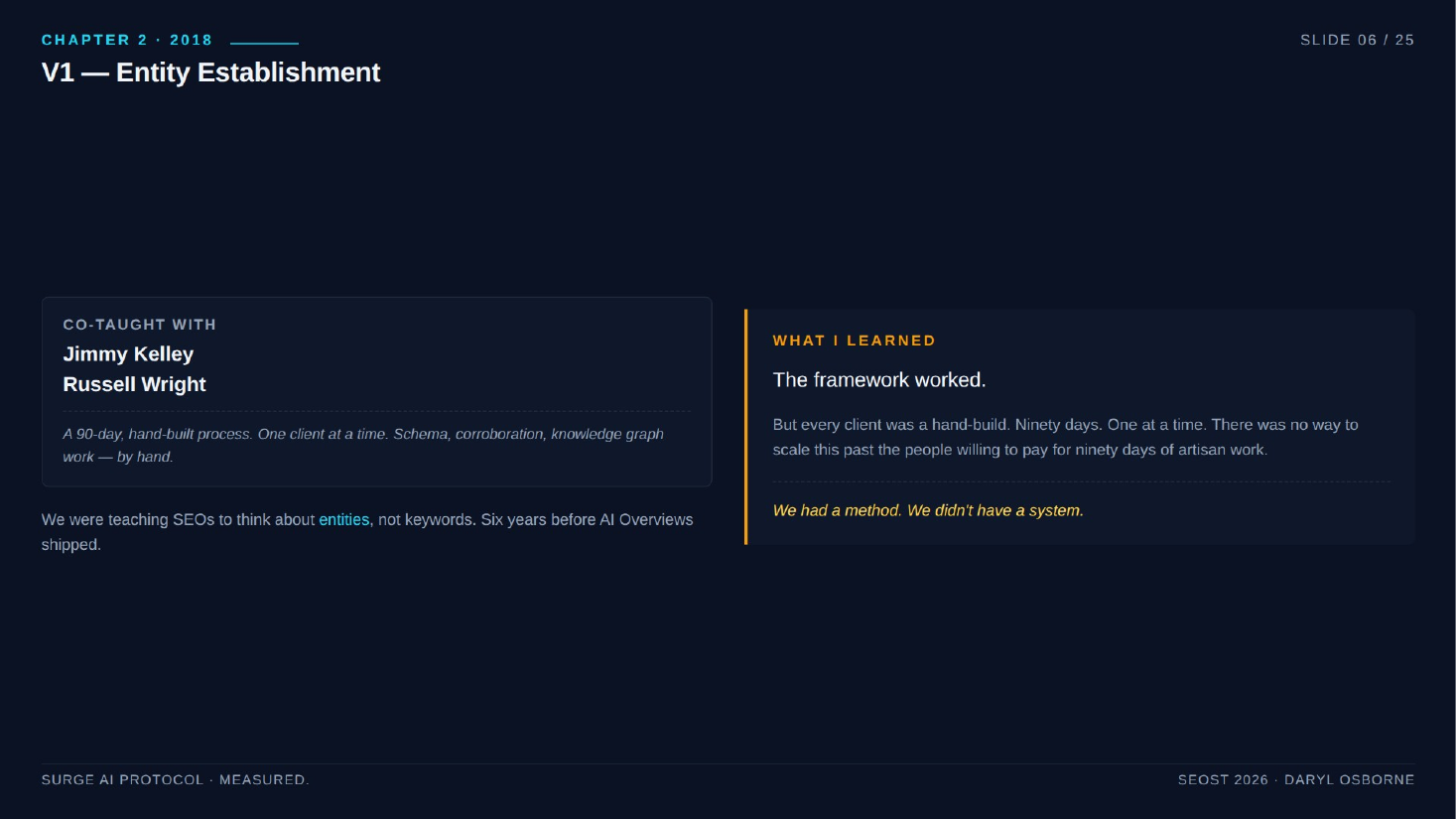
- 2018 (V1): Ran a course "Entity Establishment" with two friends, Jimmy Kelley and Russell Wright (spellings differ between the recording and the deck). Got clients into knowledge panels and stabilized brand SERPs. Every client was a hand-build, about 90 days each.
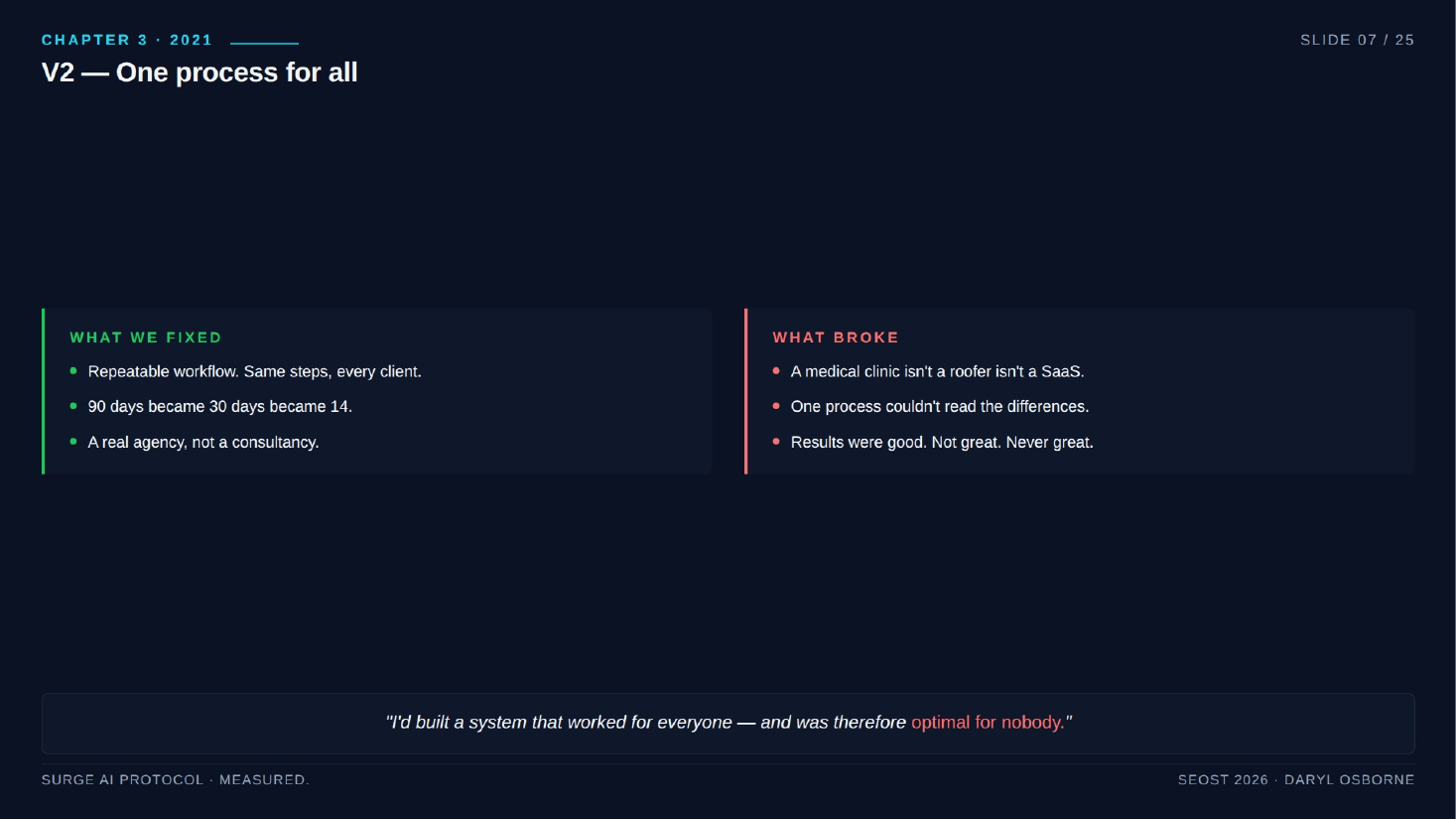
- 2021 (the pivot): Rebuilt V1 into one process for all clients; 90 days became 30, then 14, turning a consultancy into an agency with dozens of clients. The flaw: one-size-fits-all could not read that a medical clinic, a roofer, and a SaaS company have different signals. "Optimal for nobody."
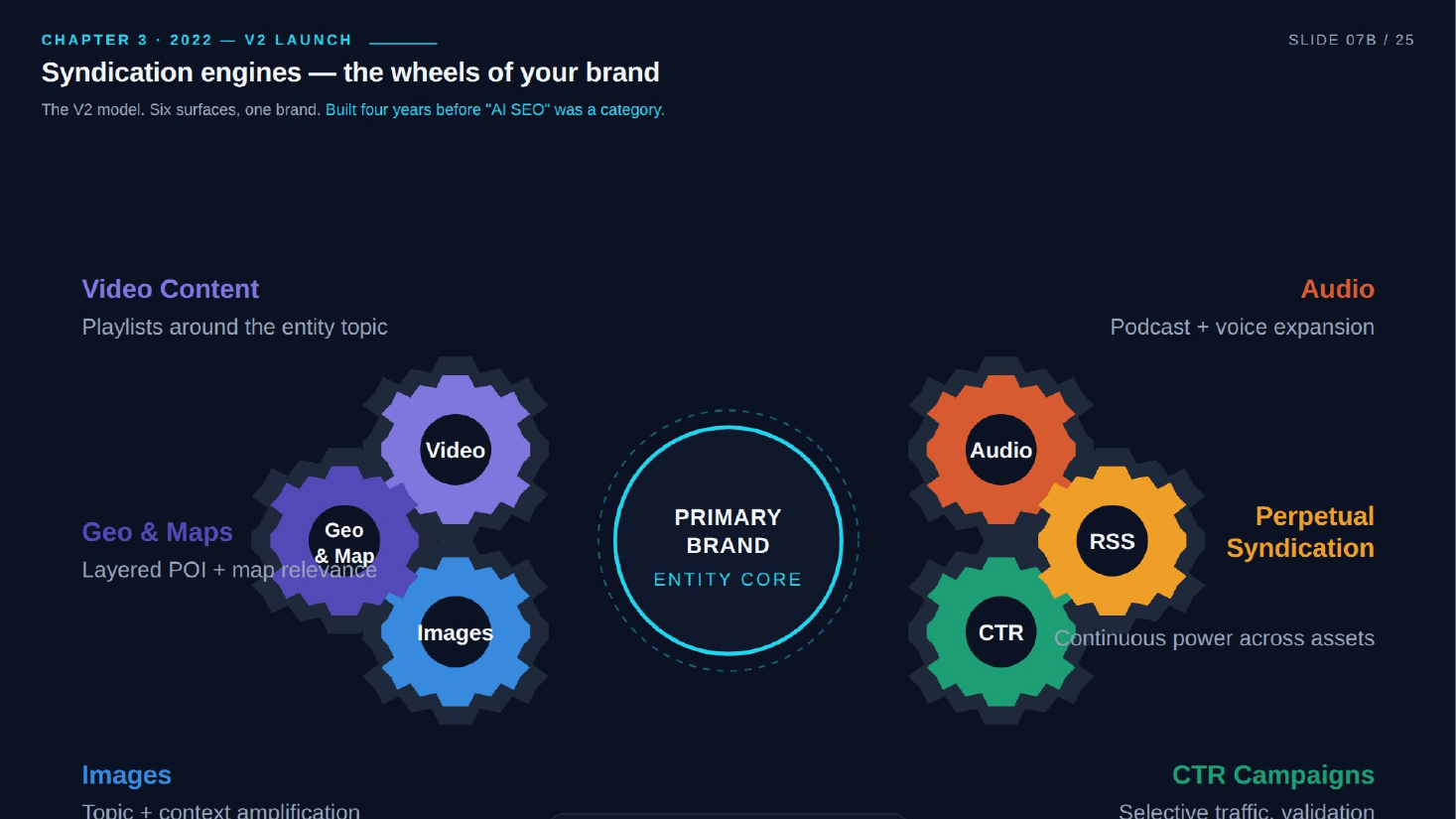
- Late 2022 (V2): Six syndication engines around a primary brand entity (video, audio, images, geo and maps, RSS, CTR campaigns). Built four years before "AI SEO" was a category and almost two years before AI Overviews shipped. The deck makes a priority claim against others who "dressed it up with new vocabulary."
- 2025 (the breakthrough): AI engines classify brands into roles within the dataset assembled for each answer.
Three eligibility filters
- Filter 1, compute eligibility (architectural): "Is this site cheap enough to parse?" Measures DOM bloat, microdata conflicts, fragment density / fragment links to nowhere, and hidden div sprawl. Failure means the engine stops spending compute, and symptoms mimic a penalty.
- Filter 2, citation eligibility (coherence and trust): "Is this source trustworthy enough to quote?" Entity recognition, independent corroboration, author authenticity. Most SEO tools stop here, playing one filter of three.
- Filter 3, answer construction: "Of all eligible candidates, which one belongs in this specific answer?" Dataset fit, intent match, best-answer eligibility.
- Thesis: "compute-eligible before citation-worthy." You cannot measure DOM bloat by asking ChatGPT.
Nine dataset roles
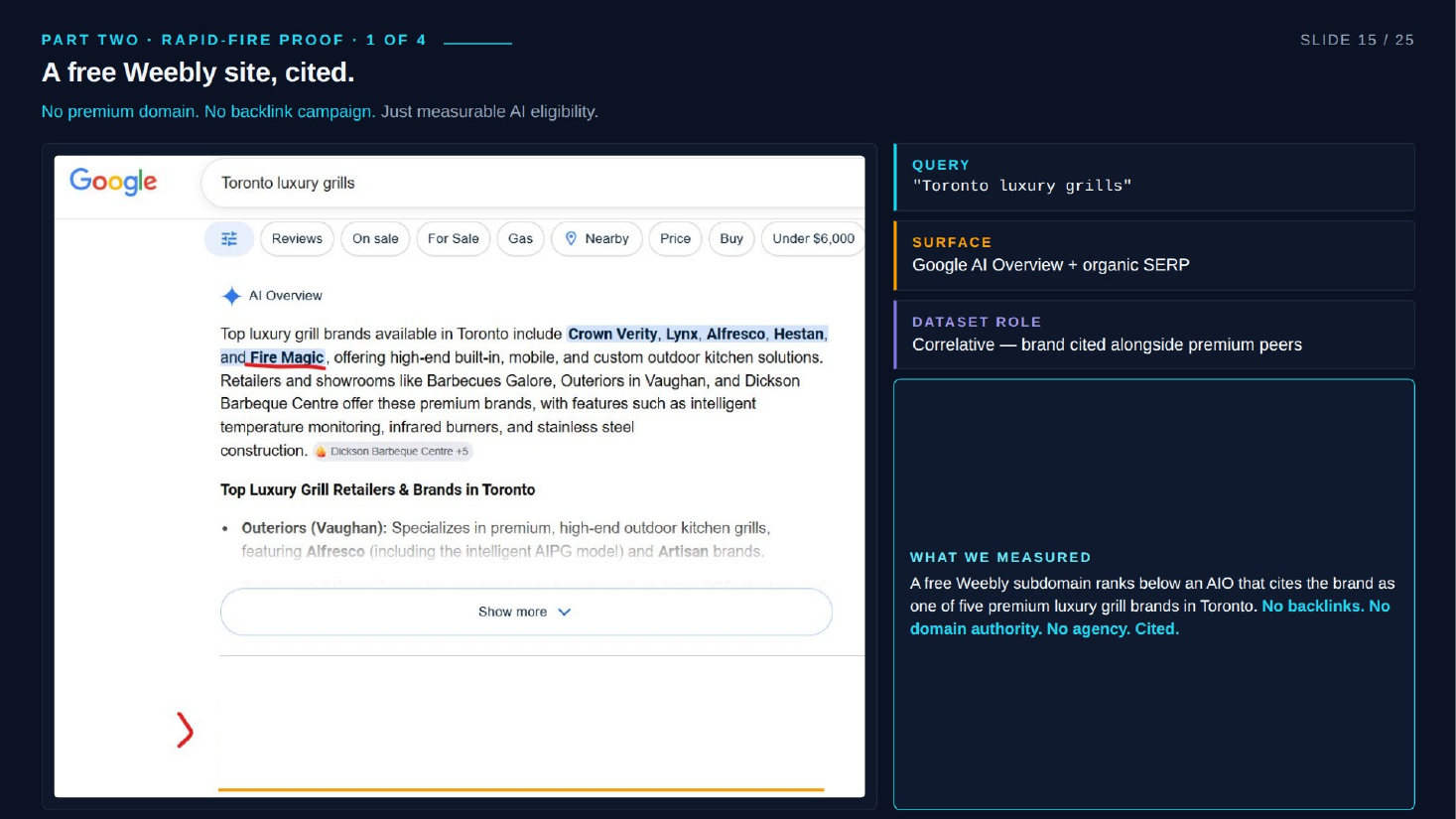
- Correlative - appears alongside peer brands in a category answer. Intervention: measure semantic alignment to the peer set. Example: a free Weebly grill site cited with peer luxury grill brands (the deck names Crown Verity, Lynx, Alfresco).
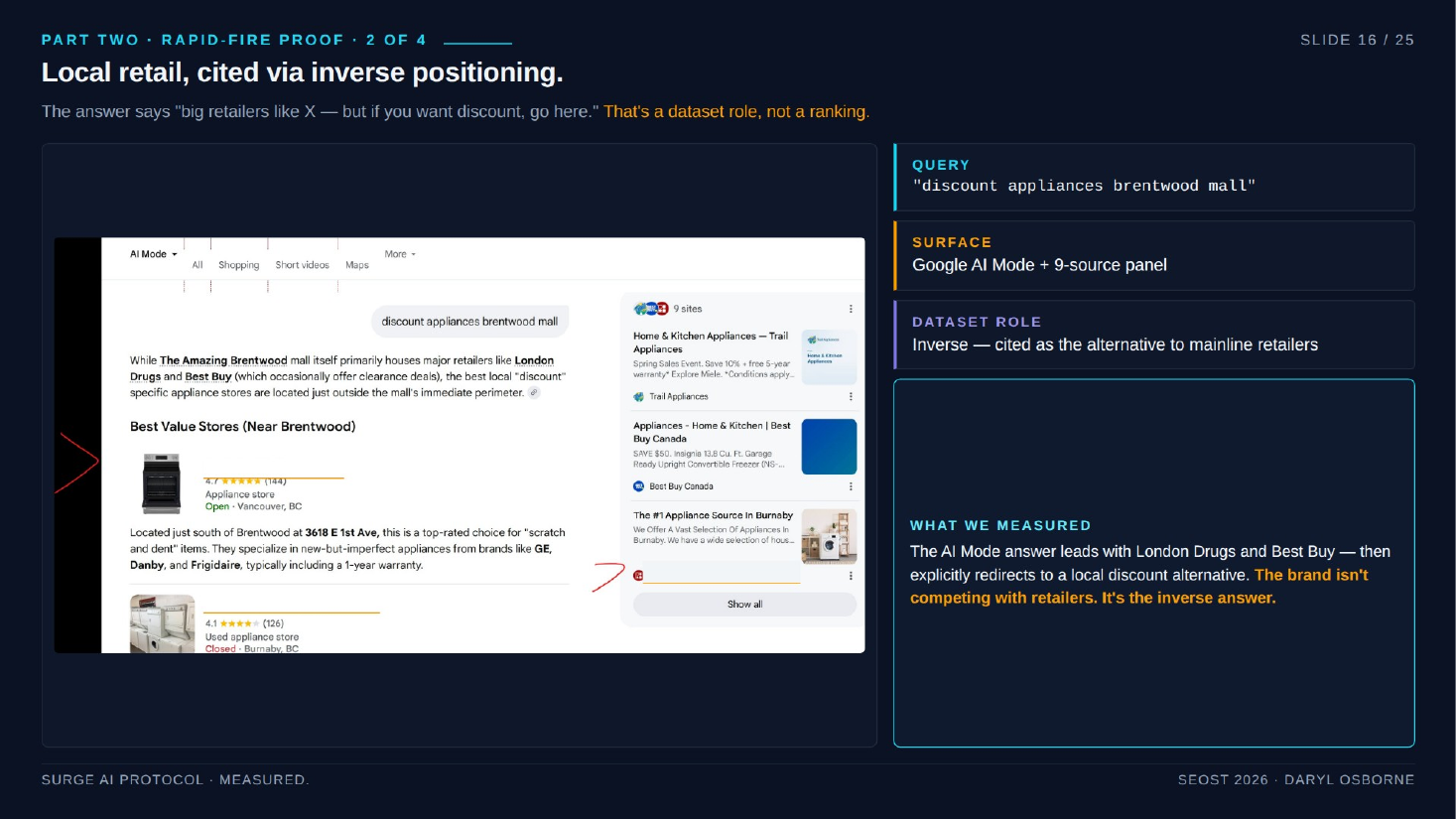
- Inverse - the engine names the obvious answers, then redirects to you as the alternative. Intervention: build explicit contrast against a strong default answer. Example: a discount appliance store cited after London Drugs and Best Buy.
- Parallel - side-by-side equivalent options (LASIK vs PRK, hardwood vs engineered floors). Intervention: measure whether you appear in the comparison set and whether the framing favors you.
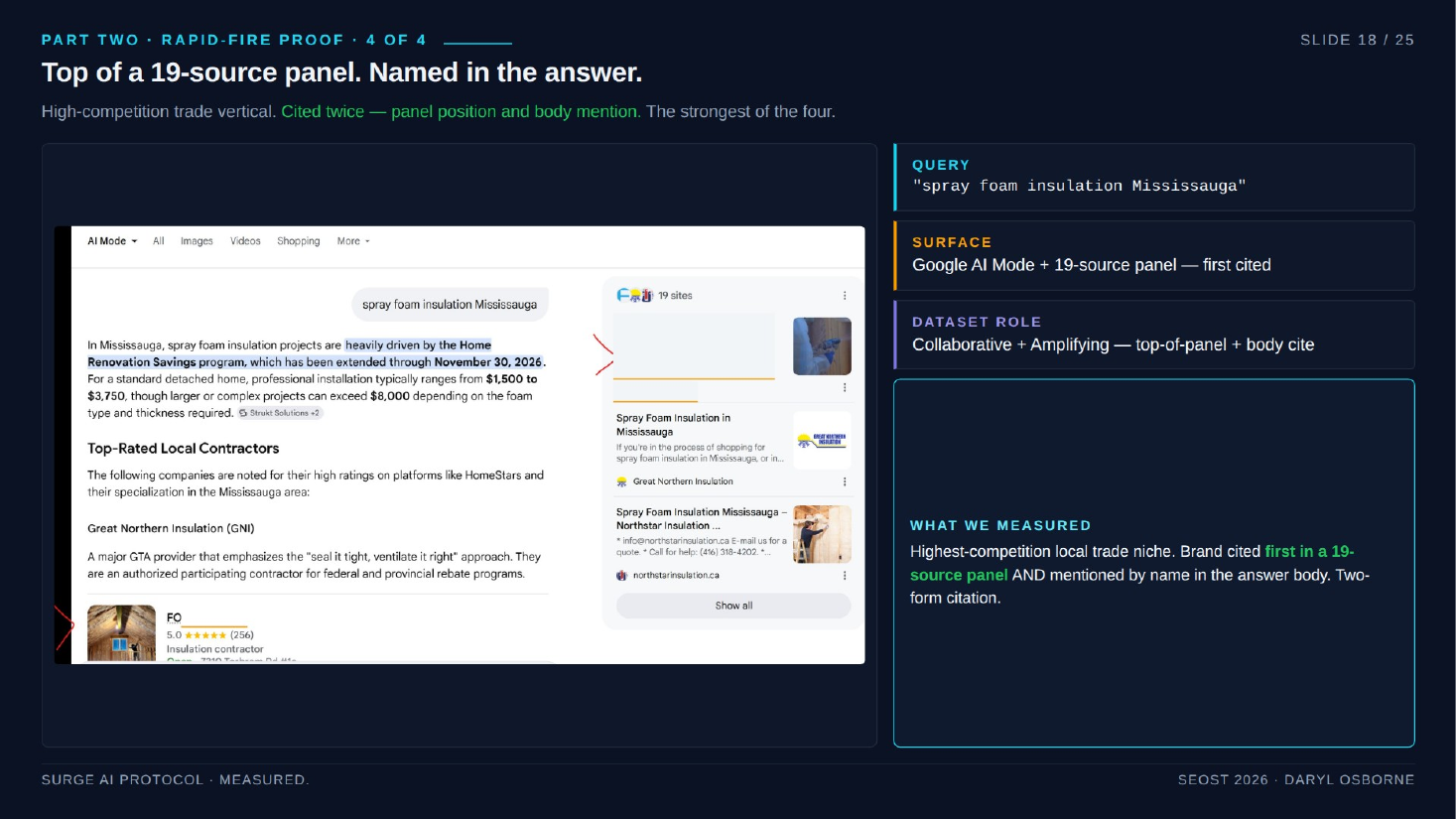
- Collaborative - multiple independent sources corroborate you. Intervention: map trusted sources in the vertical and build presence. Example: a spray foam company first-cited in a 19-source panel.
- Conflicting - sources disagree about you (different phone numbers, mismatched service descriptions, conflicting hours). Intervention: NAP and entity coherence cleanup, force consistency.
- Amplifying - UGC and community signal (forums, Reddit, review platforms), cited in the answer body, not just the source panel. Intervention: real community participation, not link spam.
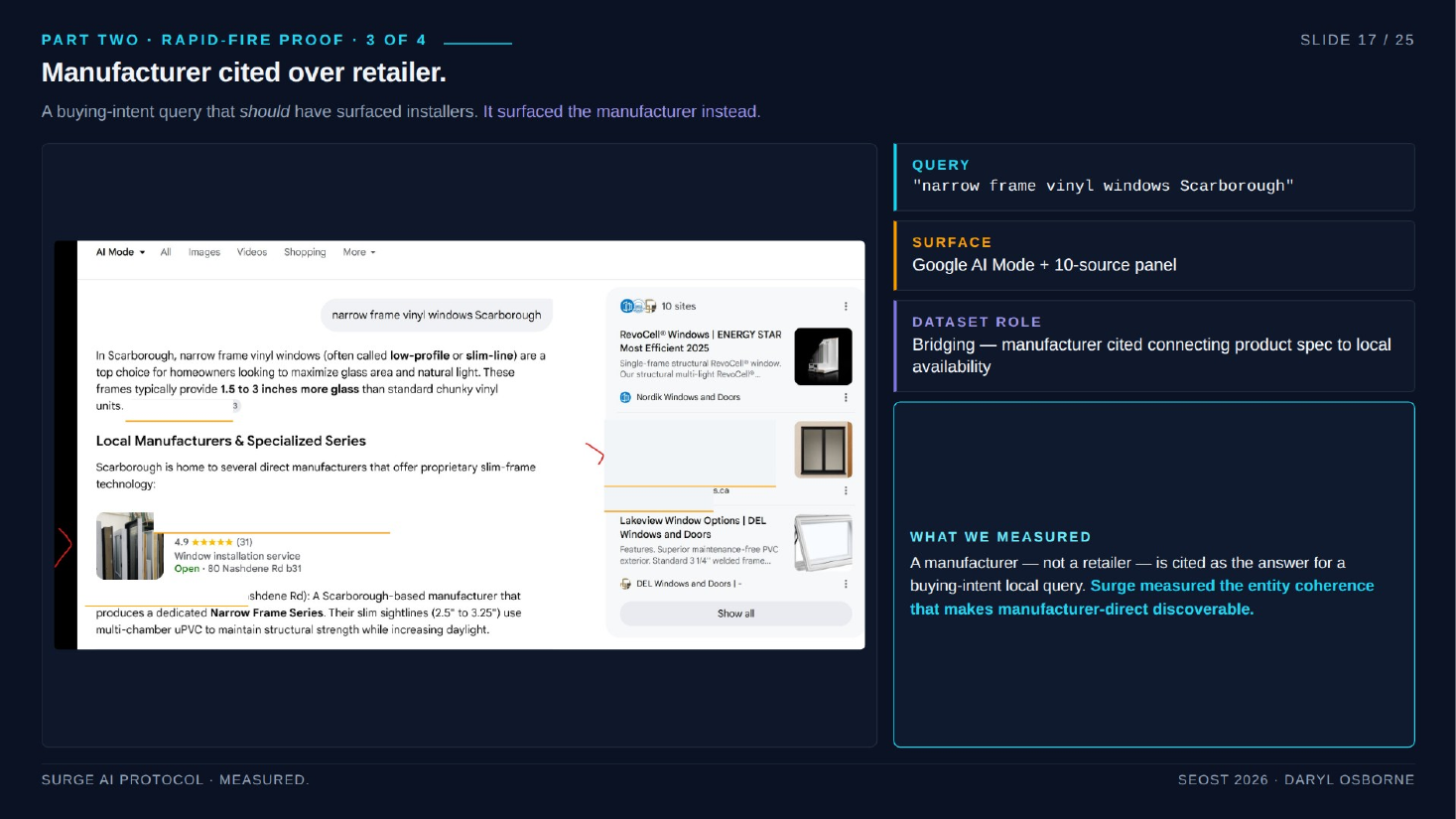
- Bridging - cited as the link between a product spec and a local availability question. Intervention: map technical concepts the brand owns and connect them to commercial-intent queries. Example: a window manufacturer surfaced for "narrow frame vinyl windows in Scarborough."
- Emergent - new patterns the engine is still forming (AI tooling, regulatory shifts, viral content). Intervention: monitor weekly and position early before the answer set hardens.
- Delegative (named only this year) - the engine uses your data (schema, GBP, structured listings, reviews, hours, services, prices) to answer without crediting you. You are trusted infrastructure but not visible authority. Explains traffic dropping while citations technically do not. Hardest intervention: convert from data source to named authority.
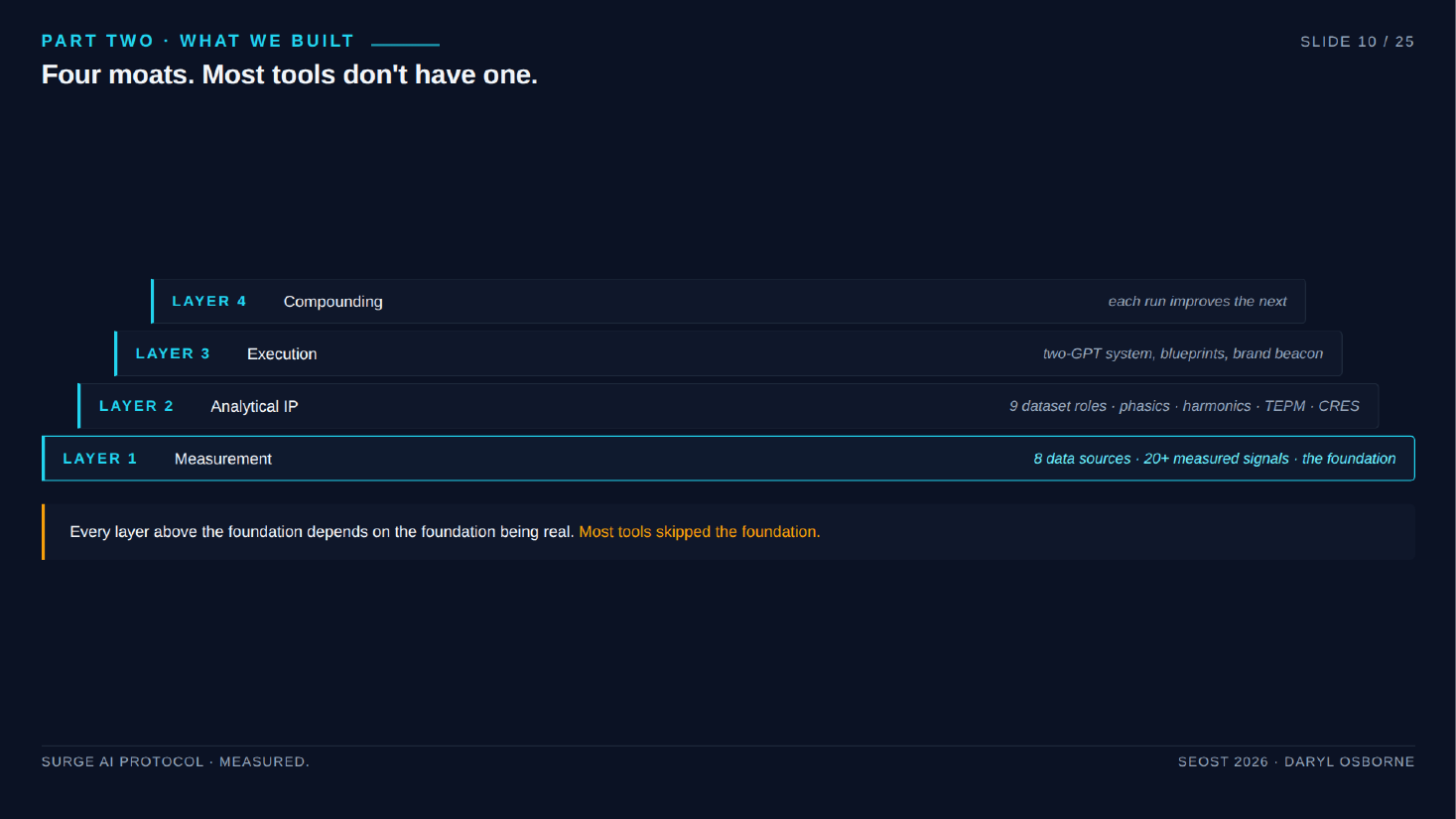
Surge V3 architecture (four layers)
- Layer 1, measurement: Eight data sources, twenty-plus measured signals per run. Three AI citation engines queried directly each run with API logs kept (Anthropic, Perplexity, OpenAI), Google NLP entity graph, real SERP data, real backlink data, real Google Business Profile data, and the live page rendered after JavaScript executes (Playwright now, not Puppeteer). Contrast claim: rivals that "measure 13 AI engines" actually call ChatGPT once.
- Layer 2, analytical IP: The nine dataset roles plus named frameworks. CRES (Citation Resonance Echo Score, how loud you are across engines, not how often you rank); Phasics and Harmonics (functions over time, whether signals are stable or bursty and how well they align); TEPM (Transmodal Entity Phase Mapping, seven phases of the buyer journey); Entity Coherence; Internal Link Equity; Signal Intelligence (five layers). Eight frameworks total, six named publicly for the first time.
- Layer 3, execution: A two-GPT system. GPT 1 "AI SEO Insights" pulls the eight sources and generates analysis; GPT 2 "Variance Tuning Companion" turns analysis into a phased Implementation Blueprint with concrete tasks and owner tags. "Brand Beacon" monitors drift over time.
- Layer 4, compounding: Day 0 baseline, day 30 second run (coverage delta, score delta), day 90 third run (trend line). Catches when an algorithm update shifts how engines weight your dataset role. Stateful, unlike stateless one-off tools.
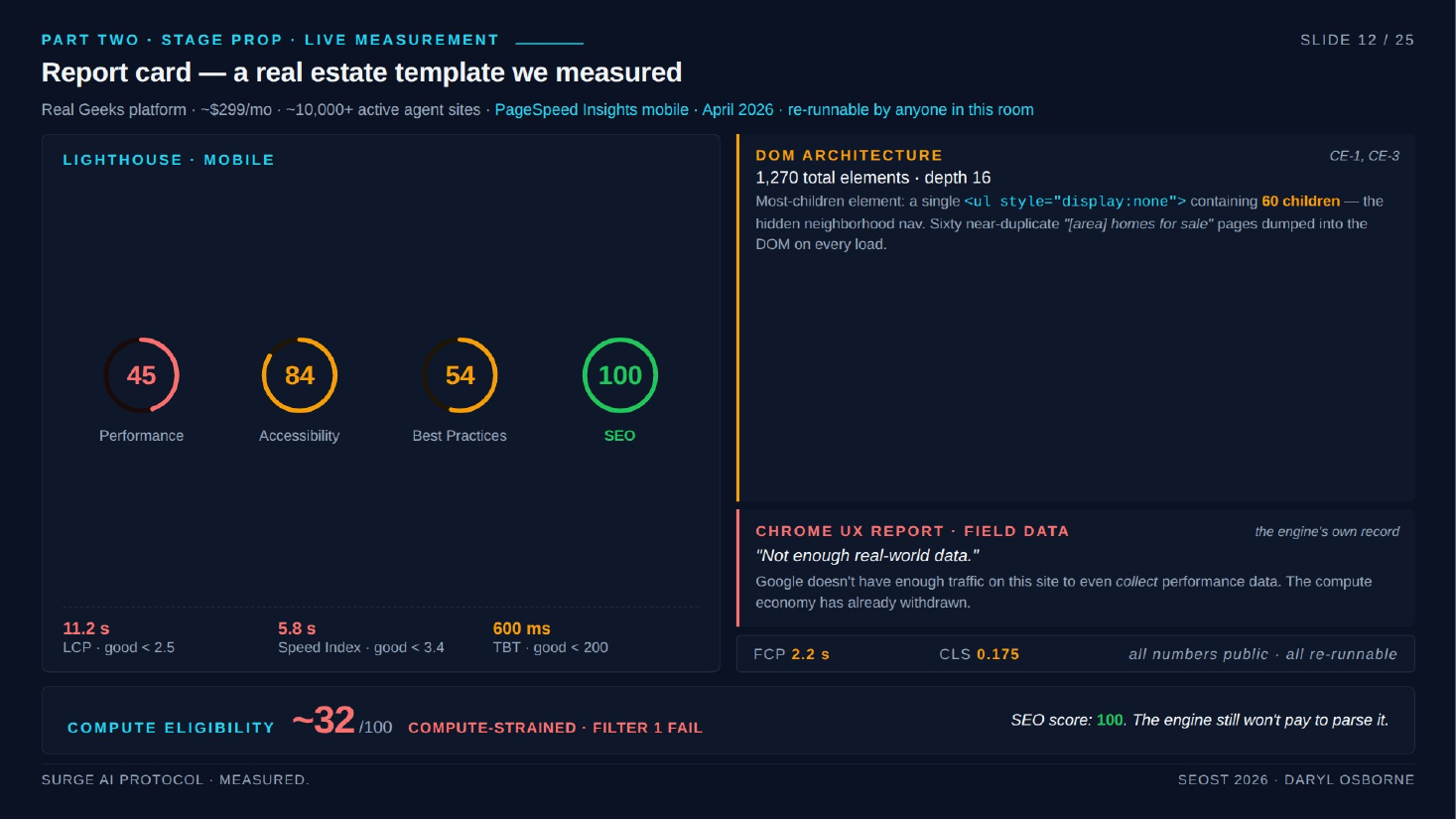
Stage-prop demo (Real Geeks template site)
- Platform: Real Geeks, about $300/month, roughly 10,000 active agent sites.
- Lighthouse mobile (PageSpeed Insights, run live): Performance 45, Accessibility 84, Best Practices 54, SEO 100.
- DOM size: 1,270 elements. Largest element was a single hidden UL with 60 children (neighborhood navigation): 60 near-duplicate "homes for sale" pages hidden by default but rendered into the DOM on every load.
- Largest Contentful Paint: 11.2 seconds, against Google's "poor" threshold of 4 seconds (nearly 3x).
- Chrome User Experience Report (CrUX): no data, not enough traffic to register.
- Conclusion: SEO score 100 yet the site never passes filter 1. An audience member interjected confirming the template's poor real-world experience.
Rapid-fire example queries (four roles, four citations)
- Toronto luxury grills: a free Weebly subdomain, no backlinks / no schema / no domain authority, cited as one of five premium luxury grill brands in the AI Overview. Correlative role.
- Discount appliances near Brentwood Mall: AI Mode names London Drugs and Best Buy, then redirects to a discount alternative. Inverse role.
- Narrow frame vinyl windows Scarborough (Omega Windows): a buying-intent local query surfaced the manufacturer instead of installers. Bridging role.
- Spray foam insulation Mississauga (deck calls it FoamIT): first-cited in a 19-source panel and named in the answer body. Two-form citation, Collaborative plus Amplifying.
- Claim on speed of results: often 48 hours, not the old 90-day timeline.
Sixty-second brand audit (three checks)
- Check 1, entity recognition: At cloud.google.com/natural-language, use "Try the API," paste your homepage text (first roughly 200 to 300 words is enough), click Analyze, open the entities tab. Pass = brand listed as ORGANIZATION with salience above 0.10. Fail = missing, near zero, or miscategorized (for example, CONSUMER_GOOD).
- Check 2, citation reality: At perplexity.ai, type your most-targeted query, read the answer, click Sources. Pass = named in the answer or your domain in the source list. Fail = nowhere while competitors are cited.
- Check 3, corroboration count: Google your exact brand name, look at the top ten organic results, count results not controlled by you (skip your own domain and social profiles). Pass = five or more independent third-party sources. Fail = only your own sites plus listings like Yelp and Facebook.
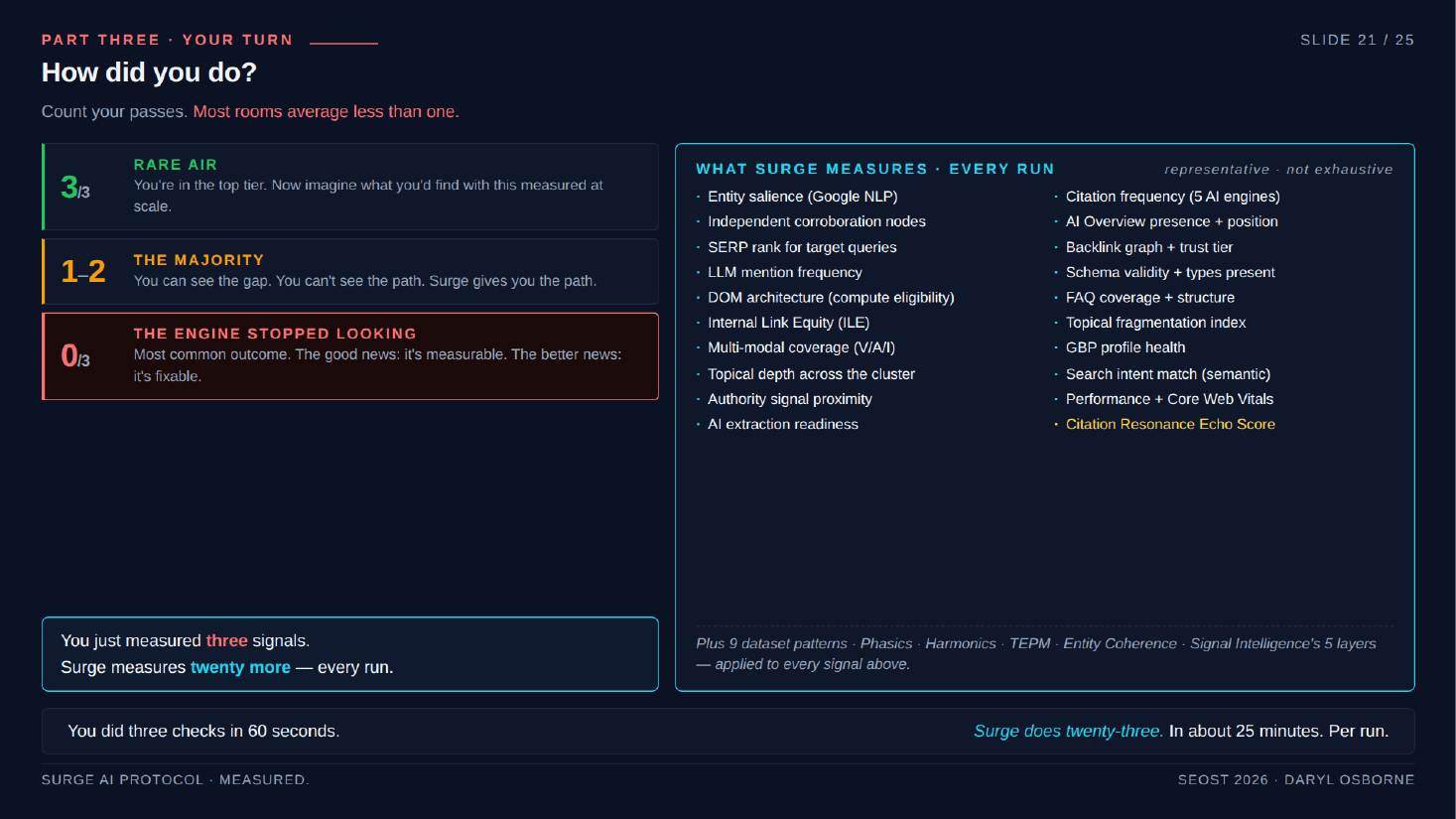
- Reveal: 3/3 is rare ("better than most of the room"); 1-2 is the majority ("see the gap, can't see the path"); 0 is the most common in the room.
- Framing: the audience did 3 checks in 60 seconds; Surge does 23 checks in about 25 minutes per run.
Closing thesis and CTA
- "For ten years we asked: how do I rank? The question now is: am I in the answer?"
- Core line: your site must be compute-eligible before it can be citation-worthy, and Surge measures both. The one repeated word framing the whole talk is "Measured."
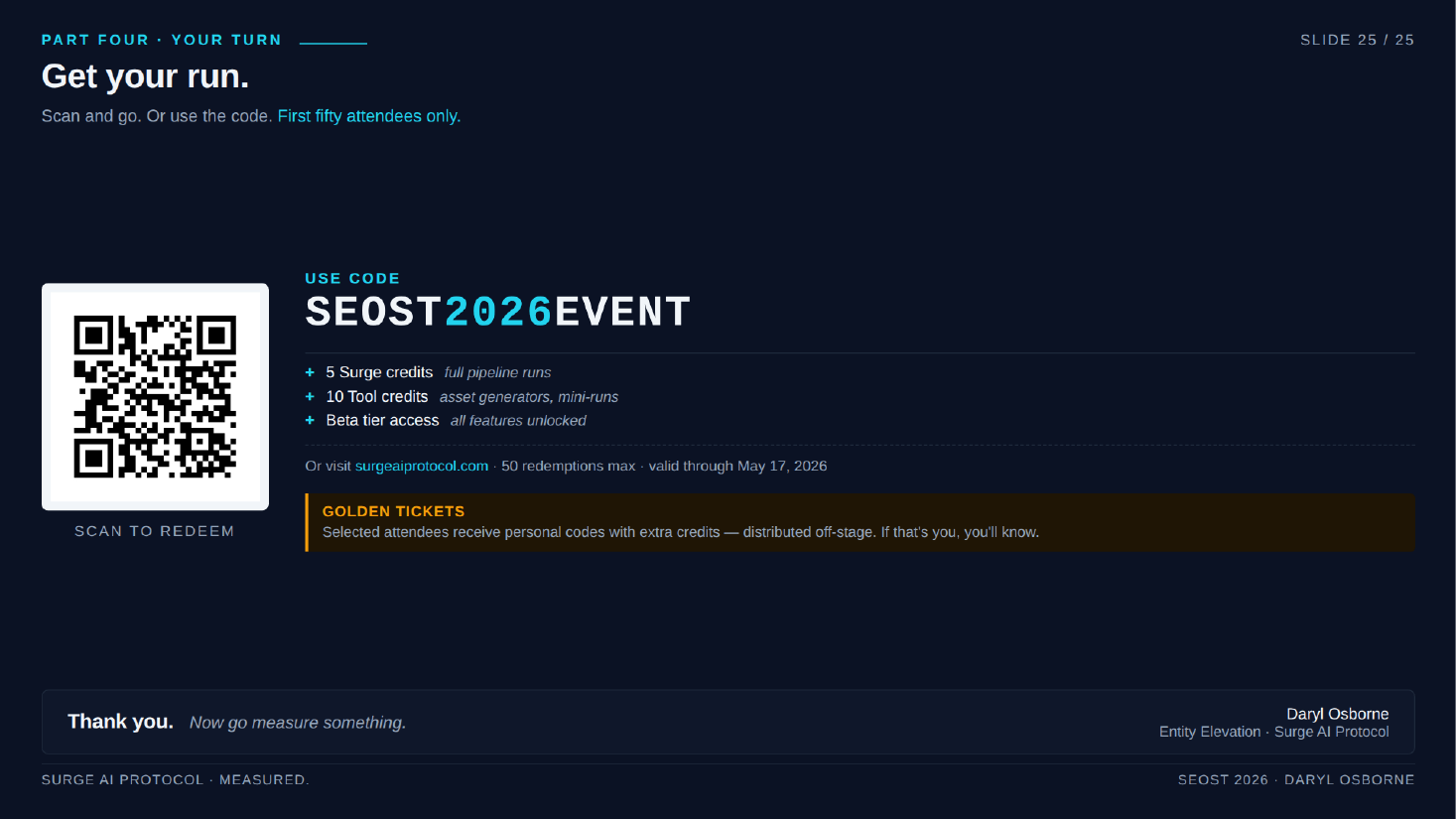
- CTA (per the deck): scan the QR, use invite code "SEOST-2026-EVENT" for five Surge credits, ten Tool credits, and beta tier access, good through May 17. Golden tickets carry more credits, and feedback earns extra credit.
Slides
Slides (27)






Source
Synthesized from the conference recording and slide deck for this Day 1 session (deck file: daryl-osborne-surge-protocol-v3-seost-2026). Attribution is filed under Daryl Osborne (the deck author); the on-stage spoken name in the recording was "Eric Lawrence," which remains unverified.