"Talk Nerdy To Me: Technical SEO for the LLM Era (Simon / limeygent)"
Simon's engineer-minded walkthrough of winning local-business content in both Google and LLM search by building from atomic facts, credible signals, and a repeatable per-section LLM audit.
On this page
- Main takeaways
- Key points
- Framing: AI slop and the new reader
- Search intent
- LLM Multi-Gate Audit (the llm-audit skill)
- LLM Wiki / knowledge graph
- Blog production and Image Banger
- DRY content and on-page bangers
- Replacing WP themes and vibe coding
- Atomic facts and signals (the theory)
- Evidence Cards (worked roofing example)
- LLM selection and scoring of local businesses
- Resources
- Slides
- Source
Simon (last name not given in the deck; GitHub handle "limeygent") delivered a technical, engineer-minded walkthrough of how to make local-business content win in both Google and LLM-driven search (AI Overviews, ChatGPT, Perplexity, Grok). The through-line: AI "slop" no longer ranks because LLMs do not read pages as documents, they chunk them into sections and judge each chunk on its own. The fix is to build content from atomic facts and credible signals, structure each section to pass an LLM's retrieval and extraction gates, and run a repeatable "LLM Multi-Gate Audit" over every section. This is a deck-only session (no recorded transcript). The day of the conference is not stated in the source.
Main takeaways
-
AI slop no longer earns AI Overviews or citations. Push-button 4,000-word AI content is cheap, fast, and client-approved, but commodity content carries no unique perspective or data, so LLMs have no reason to cite it. The slide reads "AI slop leads to no AIOs."
-
LLMs chunk content, they do not read it, so every section must stand alone. A section is judged in isolation: it either stands up or it doesn't. Audits built for the old two readers (Google's bot and a human skimmer) miss the new reader, the LLM.
-
Every answer must pass three gates, checked with six checks per section. The "LLM Multi-Gate Audit" runs a Retrieval gate, an Extraction gate, and a Grounding/Evidence gate (the precise label for the third gate is inferred from the "Evidence and Citations: The Grounding Layer" slide). Six per-section checks tell you which gate failed. Pull any section, run the six.
-
Extractability requires named referents and unique claims. If a sentence uses "it," "this," "we," or "they" with no named referent, the chunk is unquotable. The Substitution Test: if a competitor can swap their name into your sentence without lying, the LLM has no reason to cite you.
-
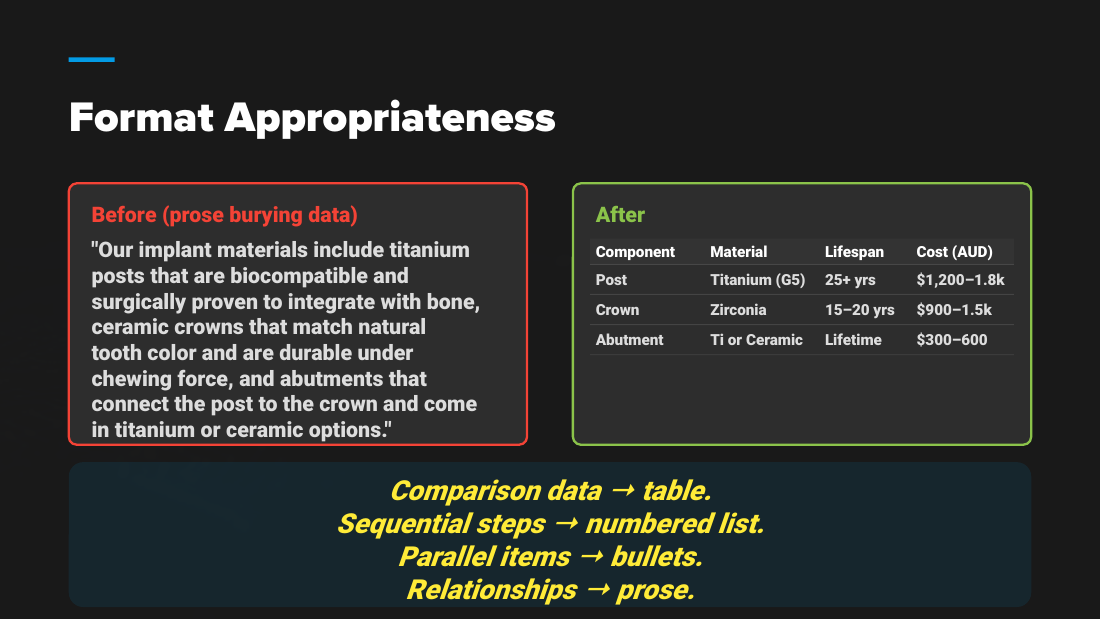
Match format to information type. Comparison data goes in a table, sequential steps in a numbered list, parallel items in bullets, relationships in prose. There are eight "fingerprints of AI slop" (not individually enumerated in the deck); three or more in one section flags slop.
-
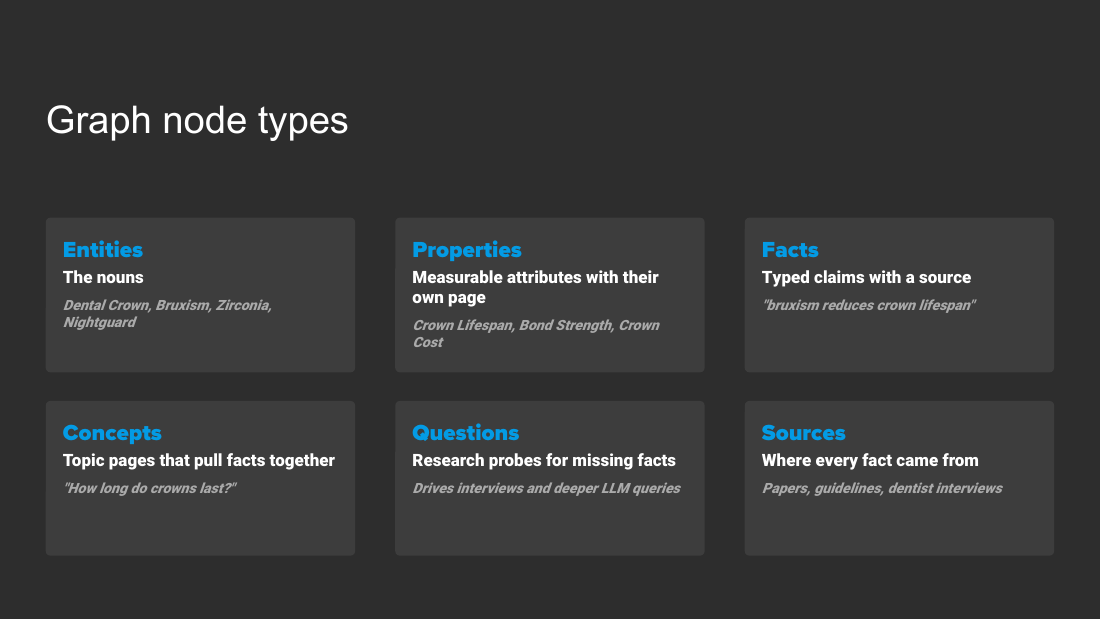
Build content from atomic facts and signals. Atomic facts (Russell and Wittgenstein: the world is made of facts, not things) are One Subject plus One Property plus One Value, verifiable and objective. Signals (Michael Spence's signaling theory, asymmetric information) are credible, hard-to-fake proofs. Facts are inputs you control; signals are scores you earn.
-
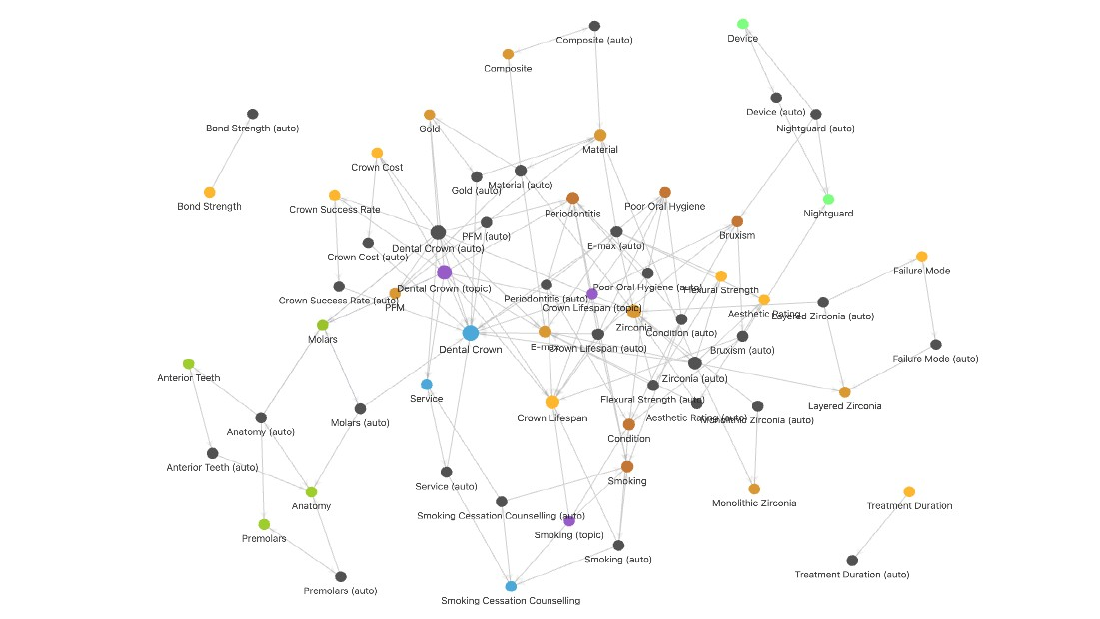
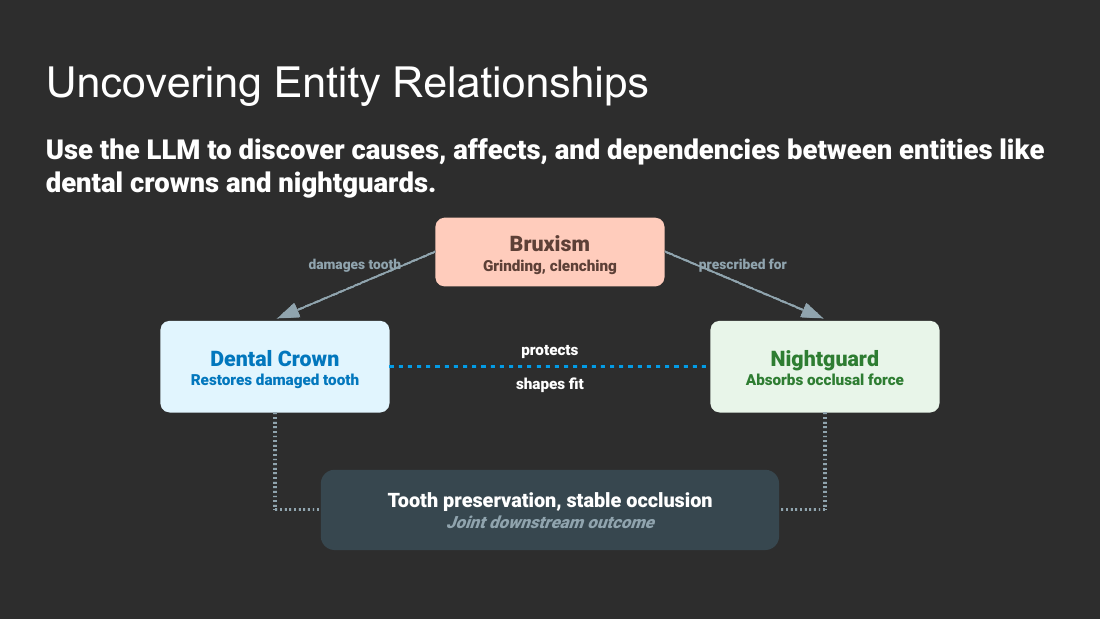
An "LLM Wiki" knowledge graph stores each fact once and reasons across articles. Make each property its own node (for example "Crown Lifespan"), so every mention auto-backlinks and the graph can infer facts no one wrote (a nightguard preserves Crown Lifespan via bruxism). One fact graph powers many articles with zero drift.
-
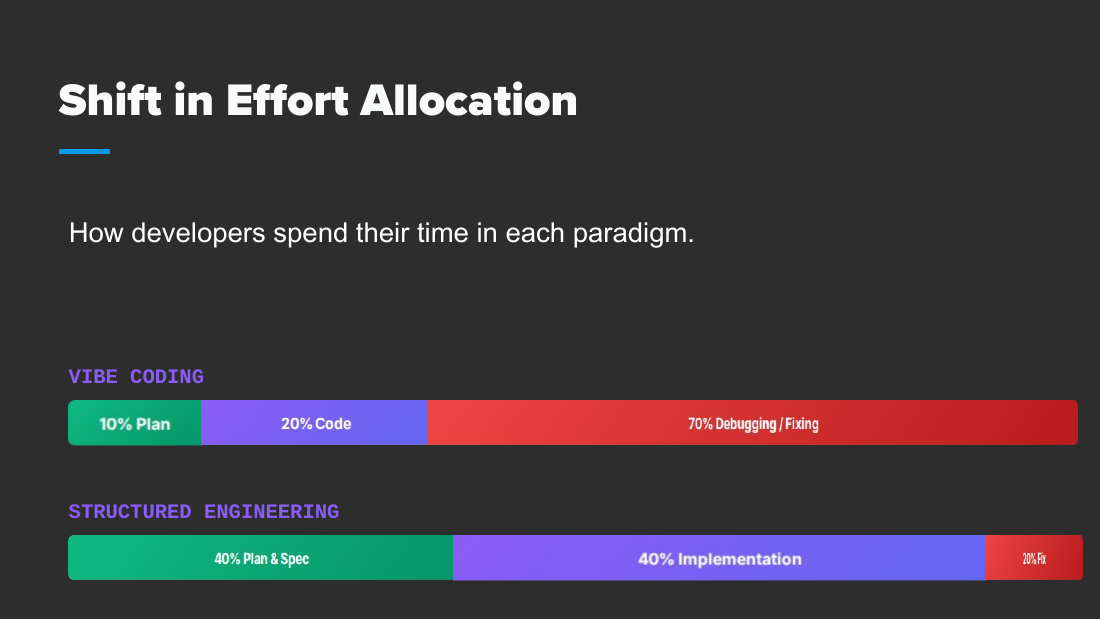
Replace vibe coding with structured engineering. Write a PRD, decompose it into discrete tasks with defined inputs and success metrics, have one LLM code and a fresh LLM audit (to beat context rot), and loop via the Ralph Wiggum pattern (Geoffrey Huntley).
-
LLMs pick local businesses by buckets of evidence. Intent match, local grounding, proximity/logistics, E-E-A-T credibility, verifiability/consistency, actionability, freshness, behavioral evidence, and spam checks. Use weighted two-step scoring (rough candidate list, then deep dive), with weights that shift by query type (emergency versus research).
-
Replace WordPress themes and plugins with AI-written HTML. Themes ship bloated CSS/JS you never use; AI writes precise HTML and updates it faster than page builders. Reviews, schema, and shortcodes can all be AI-coded directly.
Key points
Single speaker (Simon / limeygent). The session is deck-only, so points are anchored to slide themes, not timestamps.
Framing: AI slop and the new reader
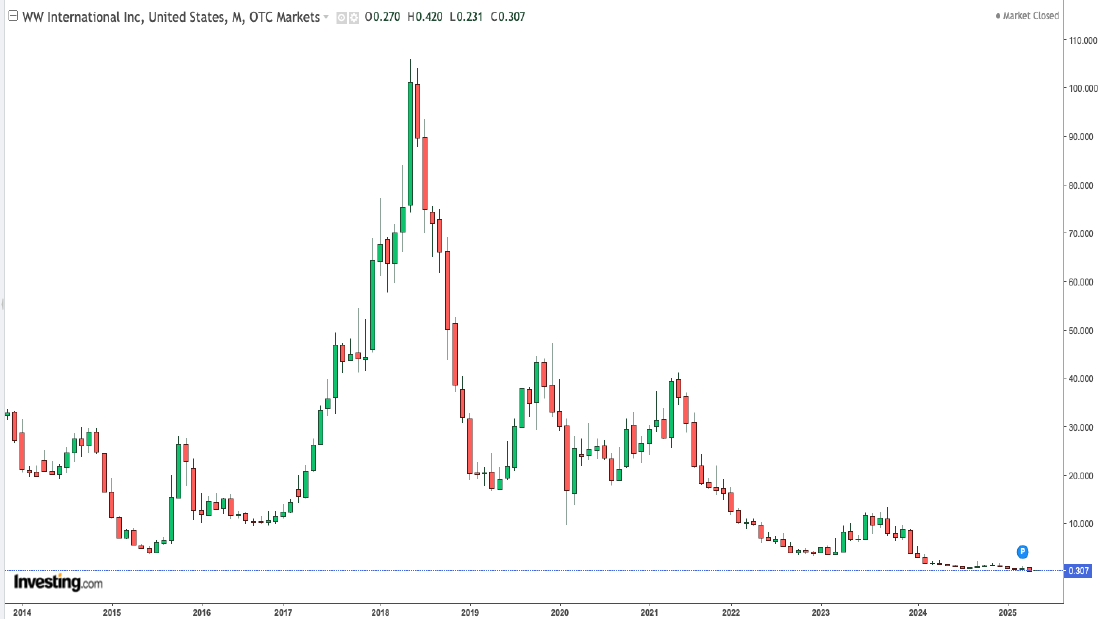
- The opener "WW?" uses The Evolution of WeightWatchers (2015 to 2026) as a cautionary brand/relevance story; the "Moral of the Story" slide is image-driven and the moral text is not printed.
- AI changed the game: push-button content on demand, 4,000 words, cheap, fast, client approved. "However..."
- Core claim: "AI slop leads to no AIOs." Slop does not earn AI Overviews.
- "Your old audit was built for two readers. Neither of them is the new reader." The new reader is the LLM.
- "AI doesn't read content. It chunks it. Your section is on its own. It either stands up or it doesn't."
Search intent
- "The Intent Behind the Intent" (trademarked phrase), hat tip to Marty Marion. Topics: Revitalizing Legacy Content via LLM Audit; The Intent Gap.
- Crisis-First heading sequence (GOOD) for an emergency plumber page: H1 Emergency Repairs (confirm immediate help); H2 Stop the Damage (utility instructions while waiting for the tech); H2 Why Trust Us (social proof, licenses); H2 Transparent Pricing (de-escalate fear of price gouging).
- Self-Centered sequence (BAD): H1 "Emergency Plumber in Chandler, AZ" (optimizing for bots), H2 "Our History Since 1983," H2 "List of All Services," H3 "Quick Links" (choice paralysis).
LLM Multi-Gate Audit (the llm-audit skill)
- "Every answer has to pass three gates." Named: Retrieval Gate; Extraction; Grounding/Evidence ("Evidence and Citations: The Grounding Layer").
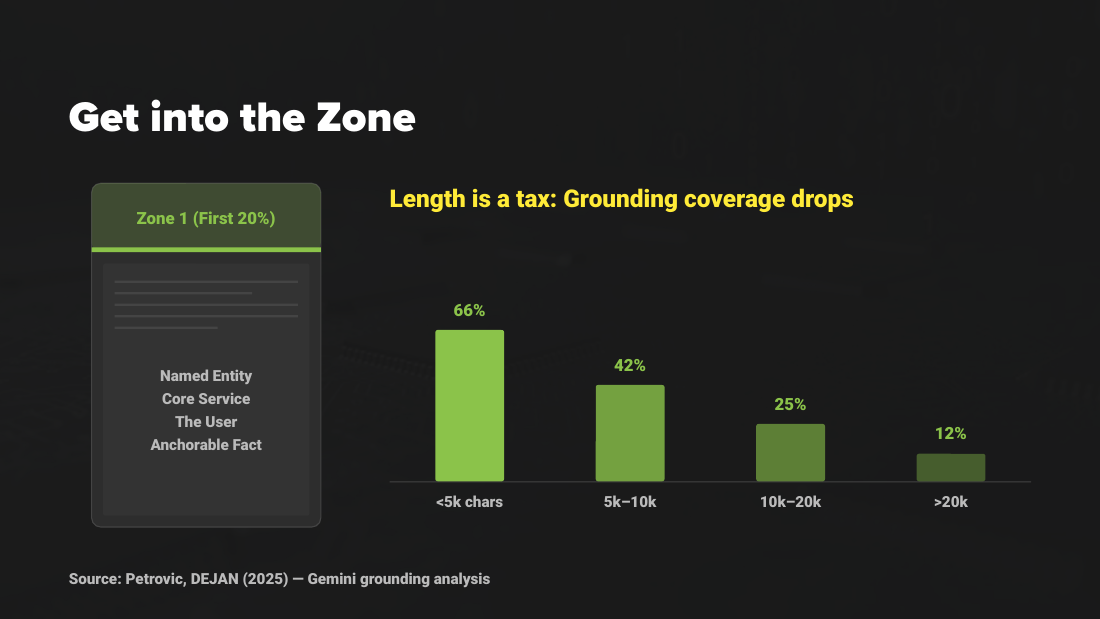
- "Get into the Zone" cites Petrovic, DEJAN (2025), Gemini grounding analysis.
- "Six checks. Run them on every section. Pull any section. Run the six. The failure tells you which gate."
- Extractability check: "If the sentence has 'it', 'this', 'we', or 'they' with no named referent, the chunk is unquotable."
- The Substitution Test: "If a competitor can swap their name into your sentence without lying, the LLM has no reason to cite you."
- Format Appropriateness: comparison data to a table; sequential steps to a numbered list; parallel items to bullets; relationships to prose.
- "Eight fingerprints of AI slop": three or more in one section indicates AI slop (the eight are not individually enumerated in the deck).
- Skill repo: github.com/limeygent/llm-audit
LLM Wiki / knowledge graph
- Inspired by a Karpathy post (x.com/karpathy/status/2039805659525644595; not independently verified).
- Pipeline: ingest raw messy data, then file and organize, then build structure (schema definitions), then build knowledge graph, then human visualization (Obsidian), then code extraction of useful data.
- Messy data sources: conference notes, videos/YT/courses/SEOST, FB groups/forums, client meetings (onboarding/discovery), client data dump (the specialist), Reddit/Quora.
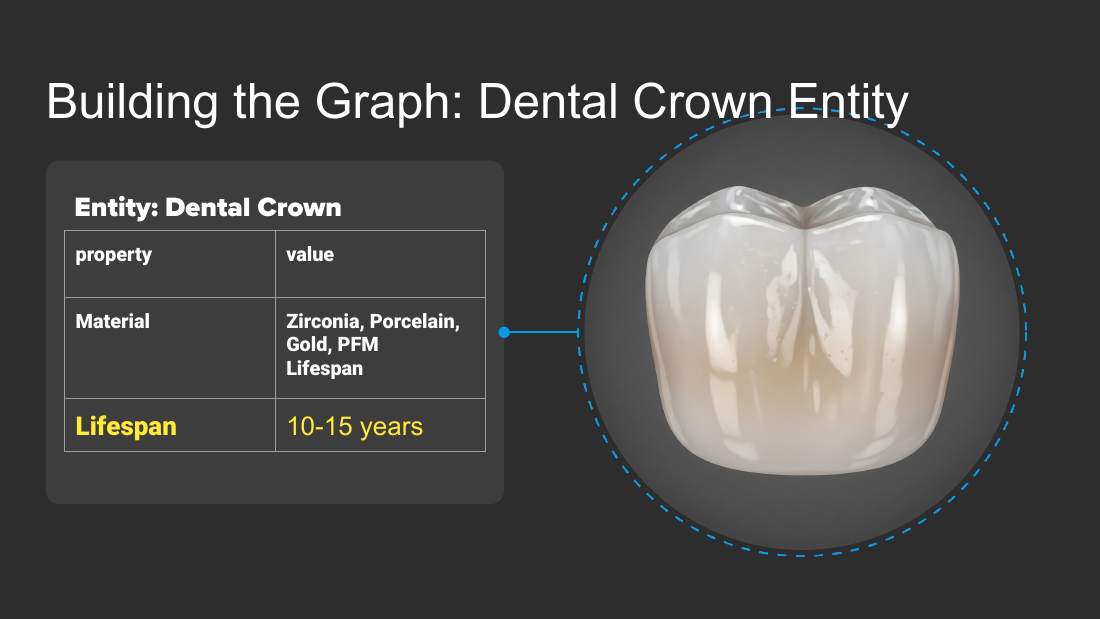
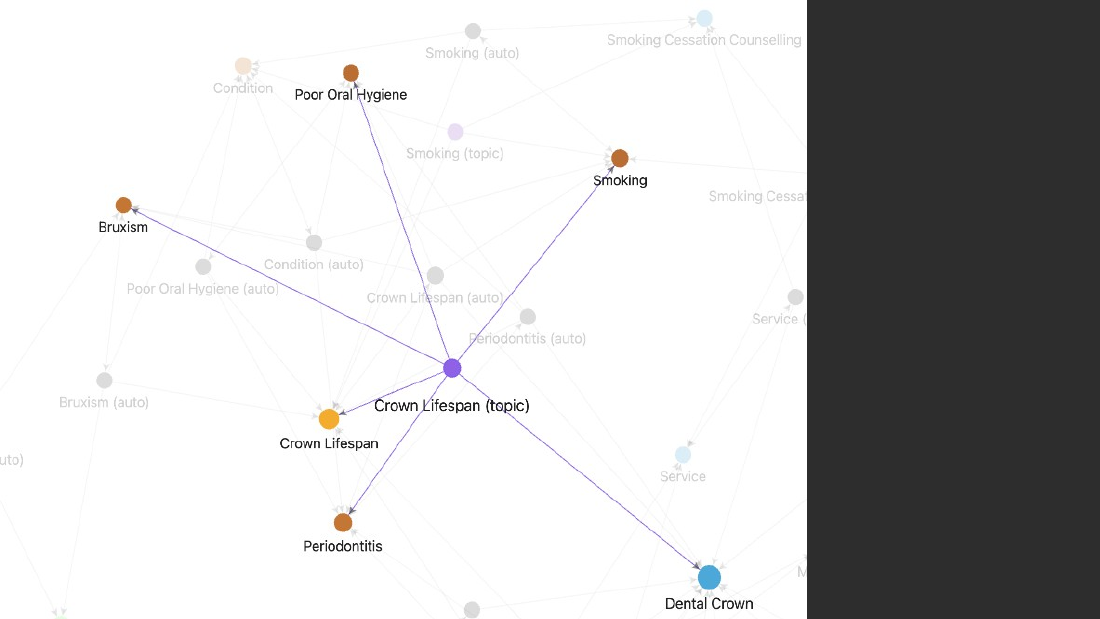
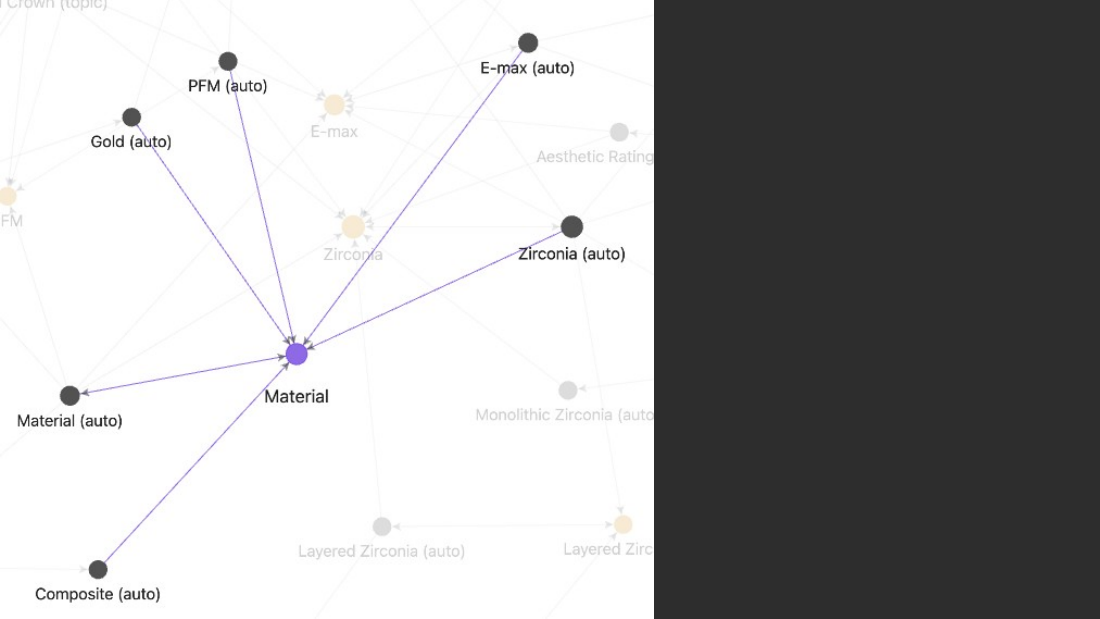
- Dental crown worked example: Material is Zirconia, Porcelain, Gold, PFM; Lifespan is 10-15 years. A generic "10-15 years" answer is commodity content with no unique perspective or clinical data.
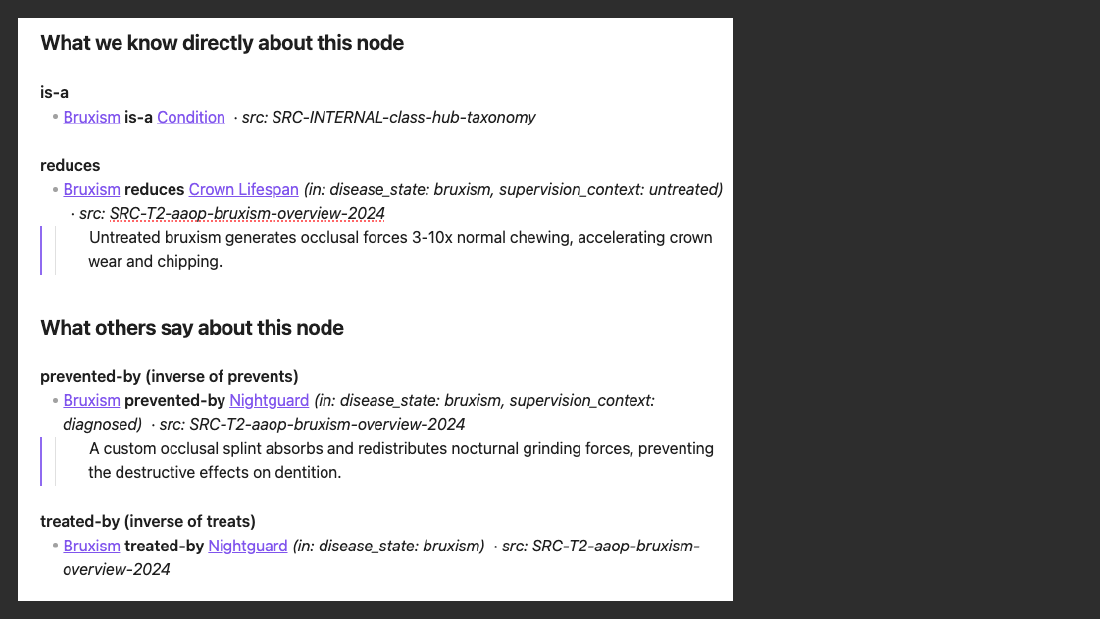
- Graph reasoning: stored "Nightguard prevents Bruxism" plus "Bruxism reduces Crown Lifespan" yields the inferred "Nightguard preserves Crown Lifespan (via Bruxism)," a fact no one wrote.
- Make the property its own node: before, Crown has lifespan "10-15 years" (not queryable); after, "Crown Lifespan" is its own node, every fact mentioning it auto-backlinks, and the page becomes a content seed.
- One fact graph, many articles, zero drift: baseline lifespan (10-15 yrs, sourced), shorteners (bruxism, smoking, periodontitis, sourced), preservers (nightguard, smoking-cessation counselling, inferred with provenance).
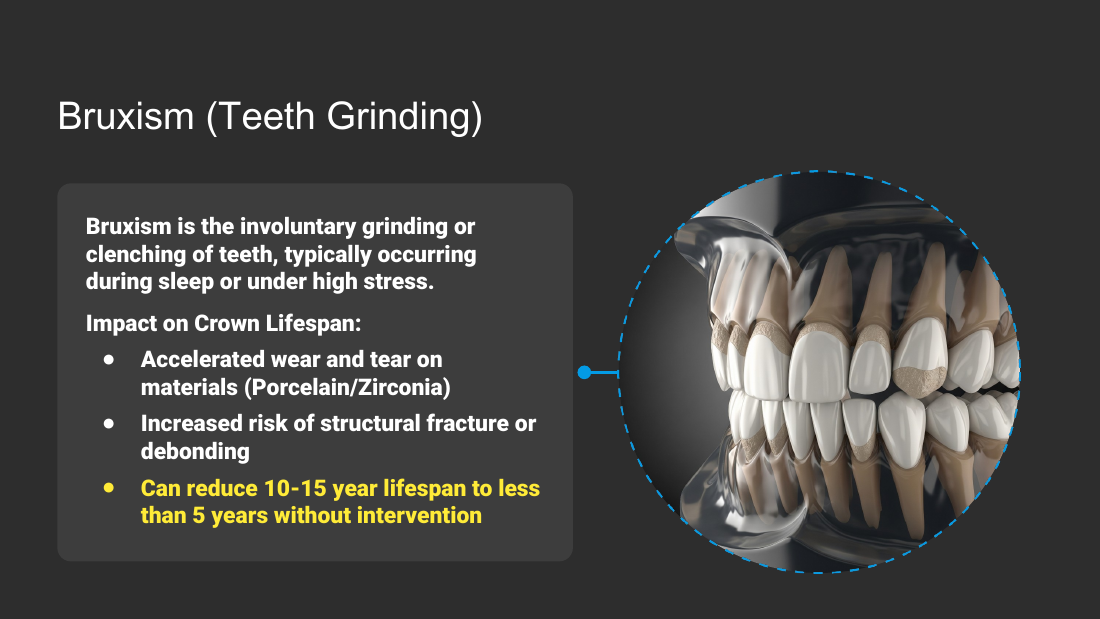
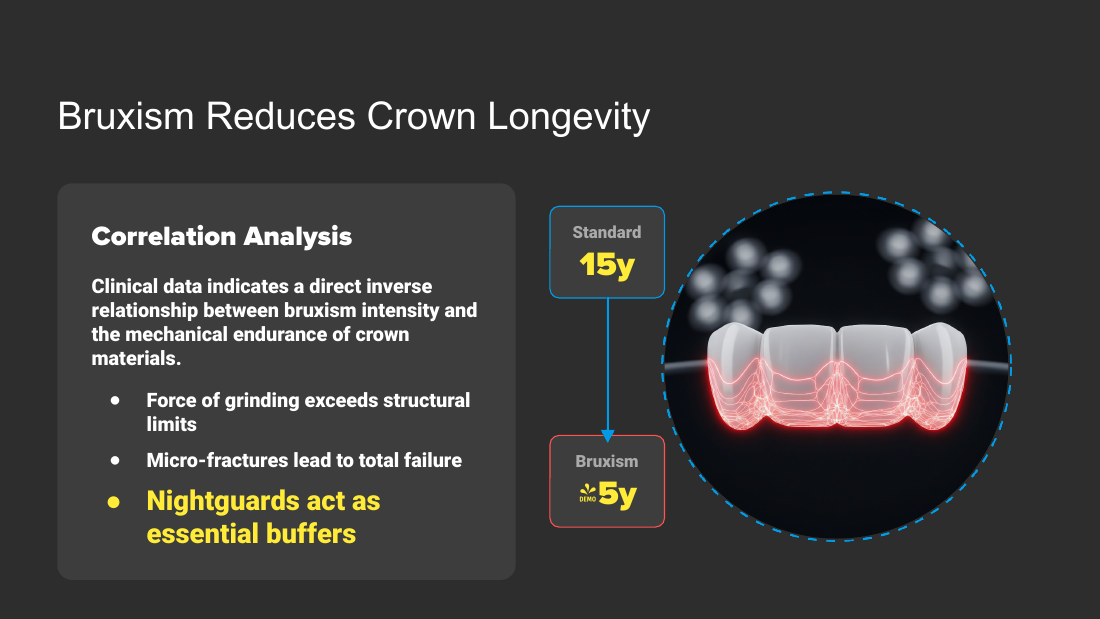
- Bruxism correlation: direct inverse relationship between bruxism intensity and crown material endurance; grinding force exceeds structural limits; micro-fractures lead to total failure; nightguards act as essential buffers.
- Crown materials Q&A: rear molars usually Zirconia (superior strength); PFM strong/durable, natural porcelain exterior, more affordable; E-max not on molars, great aesthetics, more expensive.
- Populate the graph with client questions; use Perplexity for new concepts and tie them into existing nodes; use the LLM to discover causes/affects/dependencies between entities.
Blog production and Image Banger
- Manual blog process: topic, research intent, writer (Fiverr/in-house/AI), draft review in a Google Doc, email feedback loops, client review, paste to site and strip Google Doc formatting, SEO (title/description, link to service page in first paragraph, category), featured image (Shutterstock, DepositPhotos, DALL-E), resize/compress/rename, alt text.
- AI-as-EA version collapses research/write/review into AI steps ("push the AI easy button").
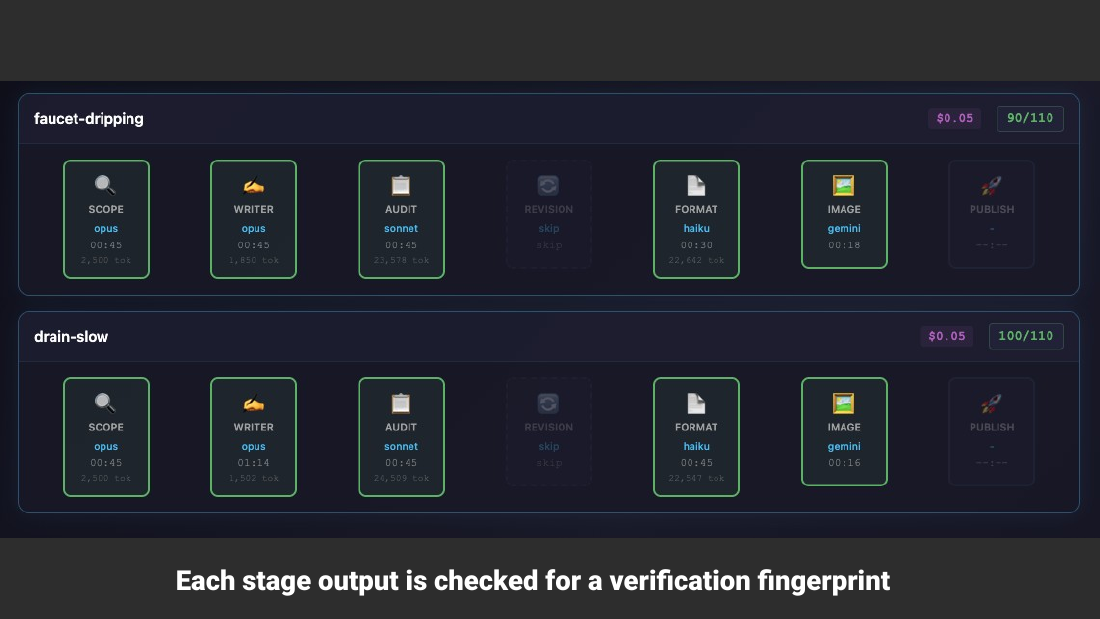
- Image Banger: read article, extract 4-6 concrete visible visual entities ("Return ONLY concrete, physical things... Primary subject first. Output as comma-separated list"), write an image-gen prompt, then generate with Google Nano Banana Pro via API (cost noted). Model reference: ai.google.dev/gemini-api/docs/models#gemini-3-pro-image-preview
- Nano Banana Pro prompt structure: photorealistic blog image; PRIMARY SUBJECT shown exactly once; supporting elements; scene-setting rules (for example a homeowner's front yard for tree trimming); composition rules ("do NOT duplicate or mirror the main fixture," one focal instance, natural object counts).
- Each pipeline stage output is checked for a verification fingerprint.
- Scope Agent: layout, background, ICP, sections and purpose, detailed writing instructions for the writer agent, meet user intent, don't stray, fan-out questions. "I have all of this in a github repo."
DRY content and on-page bangers
- DRY: if a section needs a table, put the data in the table and don't regurgitate it in prose; explain a concept once. "You don't need 4,000 words to cover a topic that needs only 800."
- Answer the search intent in the first paragraph; answer fan-out questions throughout. Google (Mueller and Sullivan) say don't turn your content into bite-sized chunks. "Content that used to rank for 1,000's of queries now only 100's" (hat tip Chris Castillo).
- On-page bangers: tables (use a thead, think entity-attribute-value); lists; topic sentences; "who are you, what you do, where you do it"; short paragraphs; images; AI-generated alt text that summarizes the article; a section with an h2 id like "why-choose-gotham-plumbers"; Zone theory.
- Reviews banger: import GMB reviews into WP as a custom post type, categorize by service, insert via shortcodes on service pages by category; bootstrap styling, ADA compliance, schema; code the whole thing with AI, no plugins.
- GMB landmark banger: "We are near the [unique landmark, copy name from Google Maps]" (example "Embassy Suites by Hilton Dallas Love Field," near Lemmon Ave and W Northwest Hwy / Loop 12); add street/sign/parking/entrance photos.
- Job-pics banger: a tech upload page, an AI-coded backend that pushes to GMB photos/posts and socials, YouTube shorts with geo, hooks into HouseCall Pro / ServiceTitan.
Replacing WP themes and vibe coding
- "No more WP Themes": bloated CSS/JS, roughly 90% unused; AI writes excellent HTML faster than page builders; replace Yoast/SEOPress; use shortcodes.
- "Vibe Coding is for amateurs": write a PRD, turn it into tasks, an LLM writes code (amateurs start here), another LLM verifies. Look into the Ralph Wiggum concept by Geoffrey Huntley.
- PRD generator: a high-level requirement, AI interviews you, AI builds the PRD, AI builds discrete tasks/user stories with defined inputs and success metrics, AI codes, output is audited by a NEW AI session (avoids context rot), Ralph Wiggum feedback loop, then human verification. Repo: github.com/limeygent/prd-task-generator
- Ralph Wiggum loop: an agent picks a user story, codes it, audits against requirements; pass leads to commit; fail passes audit and code back to the main agent, which launches a NEW agent with audit, code, and requirements; the new agent updates; repeat until passed.
- AI Context Rot: the first 50% of context is smart, the second 50% dumb (hallucinates, stuck in a rut, can't see the forest for the trees). Solution: fresh AI eyes, fresh context, objective assessment.
- AI Lessons Learned: a coding audit catches mistakes, add them to lessons-learned.md, and coding agents refer to it.
Atomic facts and signals (the theory)
- "Business From ChatGPT": unsolicited client feedback ("how did you find us... chatgpt"), referral source chatgpt.com; not new tactics, new observations turned into an SOP. ToFu/MoFu/BoFu.
- "Get Better at What You SHOULD be Doing": same evergreen principles. "LLMs are an open book, talk with them, smart child, the key is in the prompting."
- "Written by Nerds": search engines are written by software engineers; Google/GPT/Grok ranking algorithms are probably similar; on-page signals; passage ranking.
- Signal-to-Noise: a concrete ABC Plumbing block (24/7, NY license #X123456, $2M liability, fixed pricing, "90% of jobs in 4 hours," coverage radius) contrasted against generic "Welcome to Your Trusted Solution Partners" filler.
- "Back to Basics": "Don't ask the LLMs to write the copy. You'll just get War and Peace with good grammar and spelling." Write for the audience. Answer the search intent. Two questions: "Can you help me?" and "Do you know what you're doing?" To answer those: answer the search intent, show signals, provide atomic facts.
- Atomic Facts: philosophy of Russell and Wittgenstein ("the world is not made of things but of facts"). Smallest unbreakable independent unit of truth. Structure: One Subject plus One Property plus One Value, verifiable, logical, objective. Examples: Price $50; Certification GAF Certified; Credential Texas Bar License #12345; Location adjacent to Gotham City Hall; Provider Status Invisalign Platinum Provider.
- Signals / Theory of Trust: "Asymmetric Information," economist Michael Spence (1970s); without proof the buyer (Google/User) assumes the worst. A signal is a credible action revealing hidden quality (classic example: a college degree, hard to get, proves capability).
- The Engine: Atomic Facts, then Reconciliation and Verification (match "Mike" equals "Michael," validate against a trusted truth set such as a State Medical Board), then Computed Signals (Trust Signal High, Confidence Score 99%). "Facts are the inputs you control. Signals are the scores you earn." Example entity: Medspa / Medical Director / Michael Merlino, MD (FL License #420, Exp 2026-12-31).
Evidence Cards (worked roofing example)
- Evidence Cards: phone +1-555-0100; hours Mon-Fri 9:00-19:00; service "iPhone 13 screen repair, 45-60 min, $129-$159"; neighborhoods Downtown/Riverside; next booking today 3:30pm; plus address/phone/prices/booking/credentials cards.
- Licensing card: CA-CSLB-987654, Active (exp 2026-12-31); State Farm GL, $2.5M per occurrence / $5M aggregate; workers' comp SF-WC-334455 $1M/accident; GAF Master Elite #ME-112233; Owens Corning Preferred #OC-PC-445566; CertainTeed SELECT ShingleMaster #CT-SSM-778899.
- Warranty card: 10-yr workmanship; covers install defects/leaks; excludes neglect/improper maintenance; 50-yr limited manufacturer (prorated after 10); 140 mph high-wind upgrade; unlimited transfers; registered Owens #W-556677; claims@acmeroofrepair.com.
- Installation methods card: IRC 2024 plus local amendments (Cityville Ord. 123); starter course overhang 3/4"; woven shingle valley; 10"x10" step flashing; 1" counterflashing reglet; pipe boot flange under shingles; 3 magnetic sweep passes; 10mil tarps.
LLM selection and scoring of local businesses
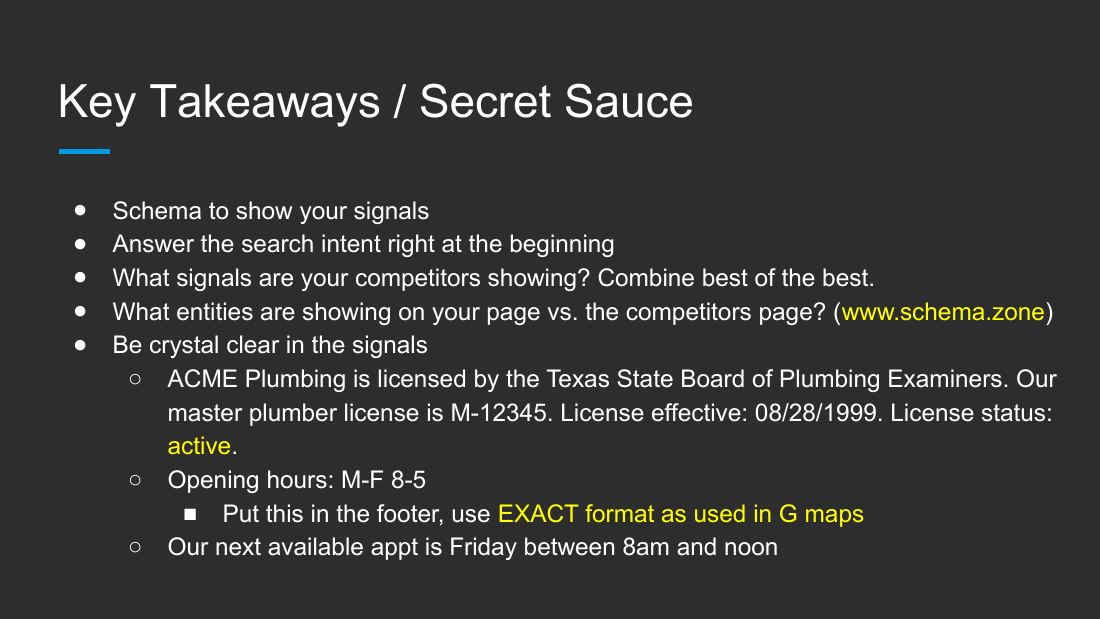
- Key Takeaways / Secret Sauce: use schema to show signals; answer intent at the beginning; analyze competitor signals and combine the best of the best; compare entities on your page versus a competitor (tool: www.schema.zone); be crystal clear; state an exact license sentence; match the hours format to Google Maps exactly and put it in the footer; state the next available appointment.
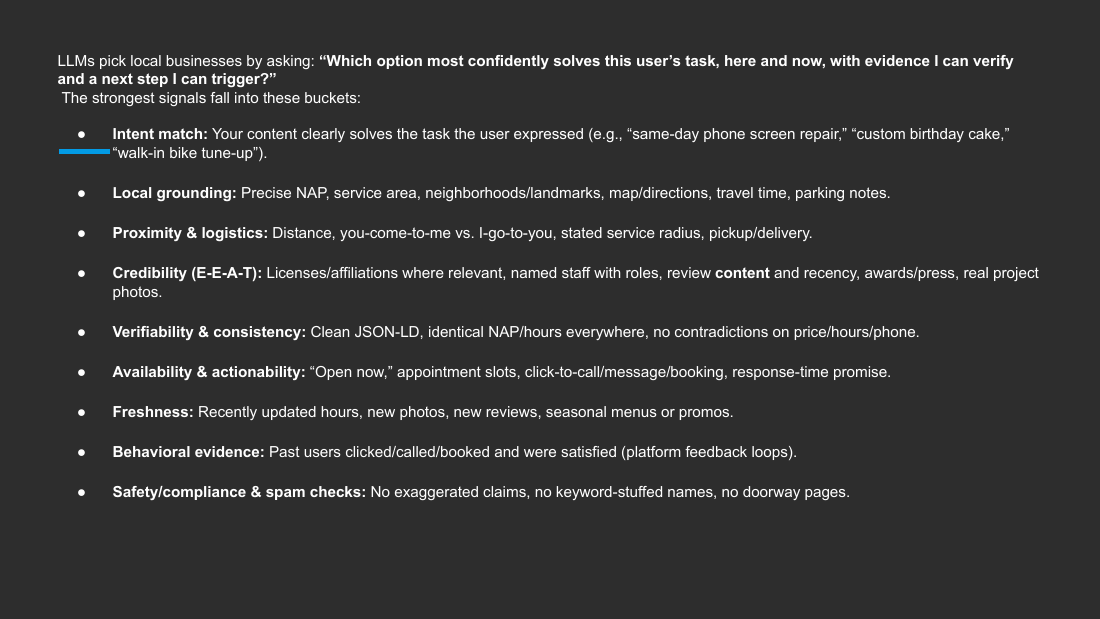
- LLM selection question: "Which option most confidently solves this user's task, here and now, with evidence I can verify and a next step I can trigger?" Buckets: Intent match; Local grounding (NAP, service area, landmarks, directions, travel time, parking); Proximity and logistics; Credibility (E-E-A-T); Verifiability and consistency (clean JSON-LD, identical NAP/hours); Availability and actionability ("Open now," click-to-call/book); Freshness; Behavioral evidence; Safety/compliance and spam checks.
- LLM 2-Step Scoring: a rough first-pass candidate list (be on GMB, Yelp, your website), then a deep dive on the short list. Weighting by query type. Emergency: Availability 30, Proximity 25, Relevance 20, Credibility 15, Verifiability 10. Non-urgent research: Credibility 30, Relevance 25, Verifiability 20, Proximity 15, Availability 10.
- LLM Council: set context, "think ultra deep," run on multiple LLMs (Grok, GPT-5, DeepSeek), and ask each to evaluate and incorporate the others' output.
- Competitor signals prompt: "Analyze these 2 pages and tell me which signals appear... in a table... Show ALL signals even if not present in either page" (placeholder URLs).
- Semantic Blocks: an h2 plus lists/tables/sentences that fulfill a purpose aligned to the page's search-query intent.
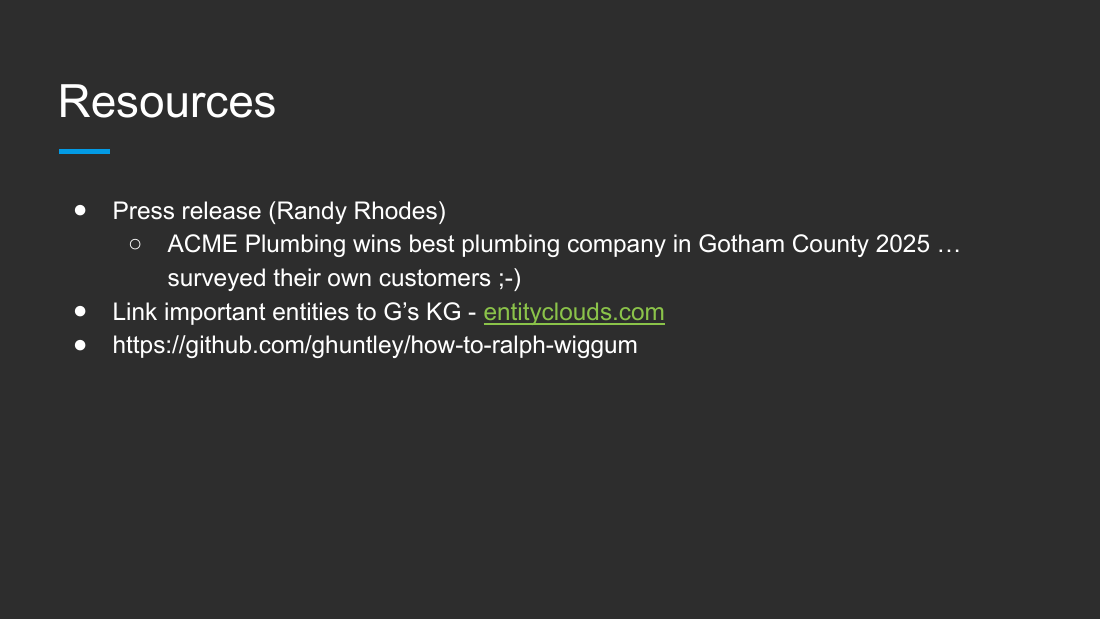
Resources
- Press release tactic (Randy Rhodes): "ACME Plumbing wins best plumbing company in Gotham County 2025" (surveyed their own customers).
- Link important entities to Google's Knowledge Graph: entityclouds.com.
- Ralph Wiggum how-to: github.com/ghuntley/how-to-ralph-wiggum
- Named people referenced: Marty Marion, Petrovic DEJAN (2025), Andrej Karpathy, John Mueller and Danny Sullivan, Chris Castillo, Geoffrey Huntley, Michael Spence, Bertrand Russell and Ludwig Wittgenstein, Randy Rhodes. Tools/models: Nano Banana Pro (Gemini 3 Pro Image Preview), Perplexity, Obsidian, Grok, GPT-5, DeepSeek, HouseCall Pro, ServiceTitan.
Slides
Slides (105)






















































































Source
This page is synthesized from the SEOST conference deck for Simon's ("limeygent") session, "Talk Nerdy To Me" (deck file: Simon - Talk NerdyTo Me.pptx, 105 slides). It is a deck-only session with no recorded transcript. Unknowns are marked inline (speaker's last name, conference day, and the exact label of the third audit gate).