Brian Winum - LLM Authority Hacking and Stacking with E-E-A-T
Brian Winum's Day 1 system for winning LLM and AI-overview visibility by treating E-E-A-T as the spine, stacking llms.txt files, and manufacturing off-page authority.
On this page
On Day 1, Brian Winum (a New York agency owner with 20-plus years in digital marketing, partner at MAXBURST Web Design and MAXPlaces Marketing) delivered a hands-on system for winning LLM and AI-overview visibility by treating E-E-A-T as the spine of everything. His thesis is "Brand. Authority. Data." The talk walked through an on-page stack of heavily customized llms.txt files and supplemental files, the redundant crawl paths that force bots to find them, an off-page program for manufacturing authority signals, and authorship/provenance defense plus Common Crawl measurement. The tactics are deliberately gray-hat, and he was candid that he "spams the shit out of" listicles and builds, buys, or steals roundups.
Main takeaways
-
Everything ladders back to "Brand. Authority. Data." and E-E-A-T. Strong brand signals (Helpful Content Update era), authority by citation, and proprietary "commodity" data form a trifecta that both Google and AI models reward. He maps it to Google's three News provenance signals: widespread coverage, frequent citations, and substantial original reporting.
-
An llms.txt file only works if you over-invest in it. Treated like default Yoast schema pushed by a plugin, it gets ignored. Treated like heavily customized schema (a custom header "AI elevator pitch," a custom footer of third-party validation), it earns AI comprehension and citations.
-
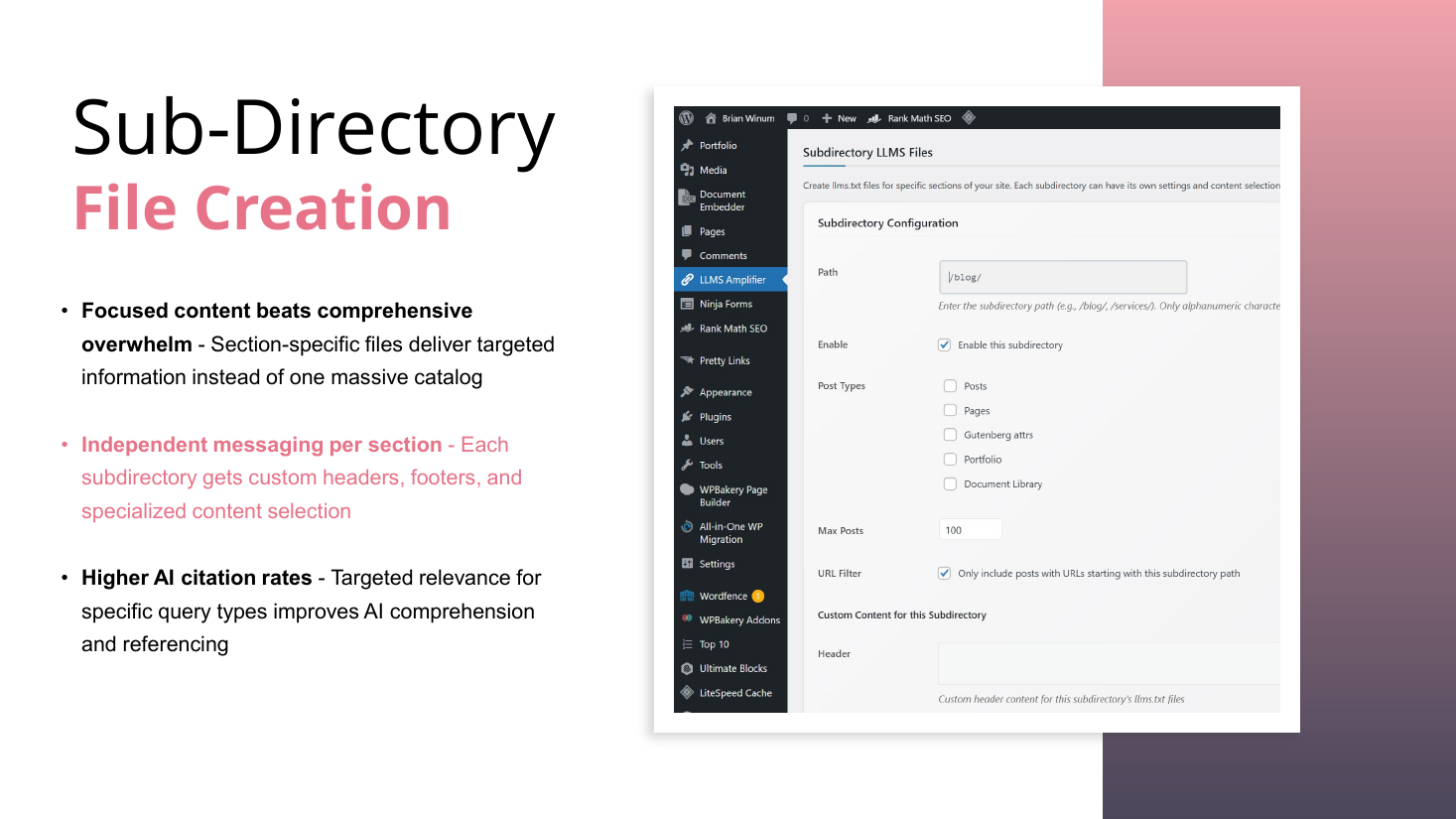
Build a stack of files, not one file. Beyond llms.txt and llms-full.txt, he creates separate FAQ, glossary, and review files, plus JSON, annotated markdown, and plain HTML variants, and sub-directory llms.txt files per blog, service, and location for niche and geo relevance.
-
Engineer redundant crawl paths so no bot can miss the files. Internal file cross-referencing, a dedicated LLMS XML sitemap, site-wide meta link-rel header injection, robots.txt references, link prefetching, and custom MIME types in HTML meta tags.
-
A JSON llms-index file adds corrections, agent guidance, actions, and a manifest. A corrections section to fix AI hallucinations, scenario-based agent guidance (including "do NOT recommend me for X"), an actions/routing section, and a SHA-256 hashed file manifest so crawlers detect changes fast.
-
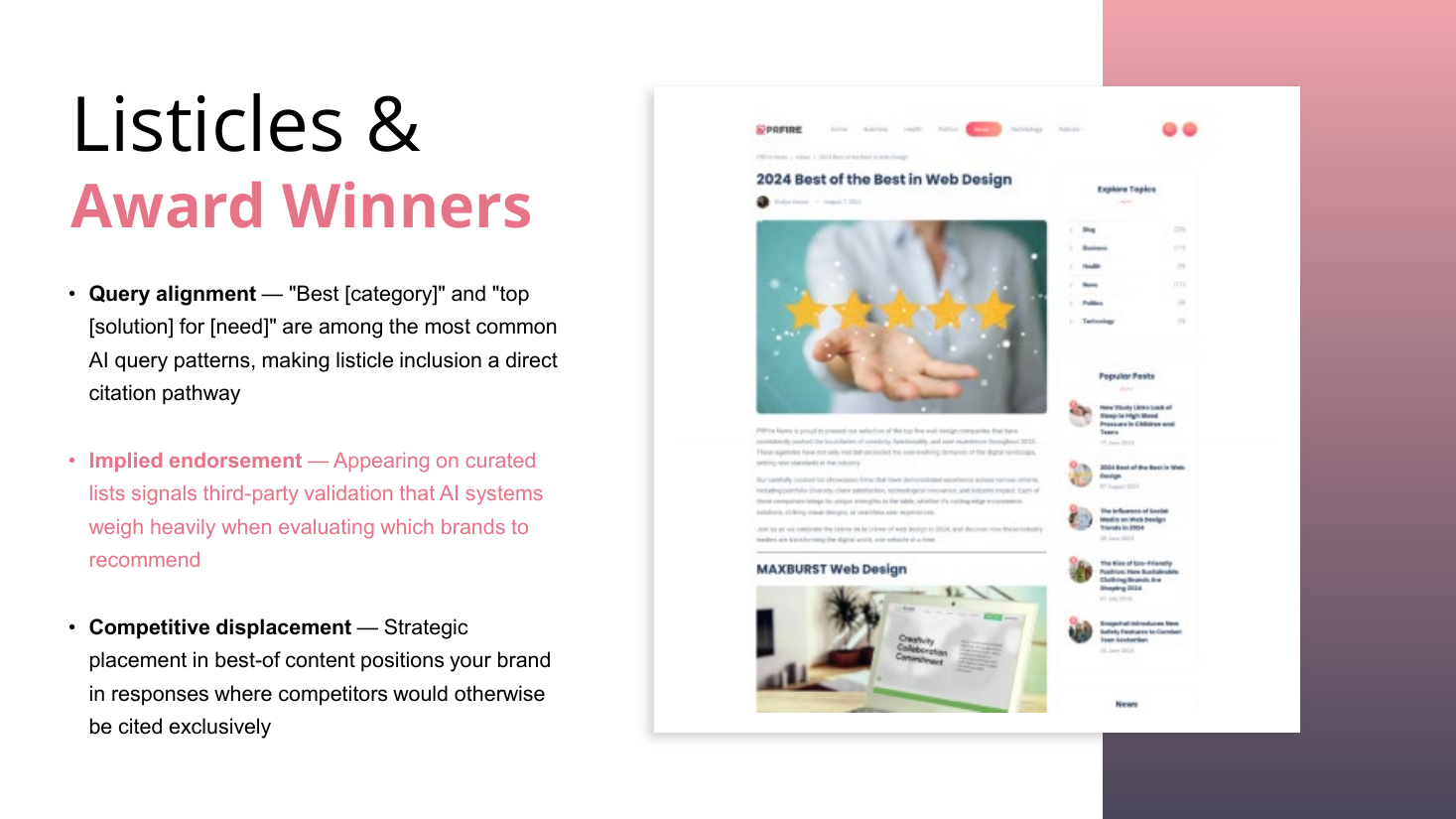
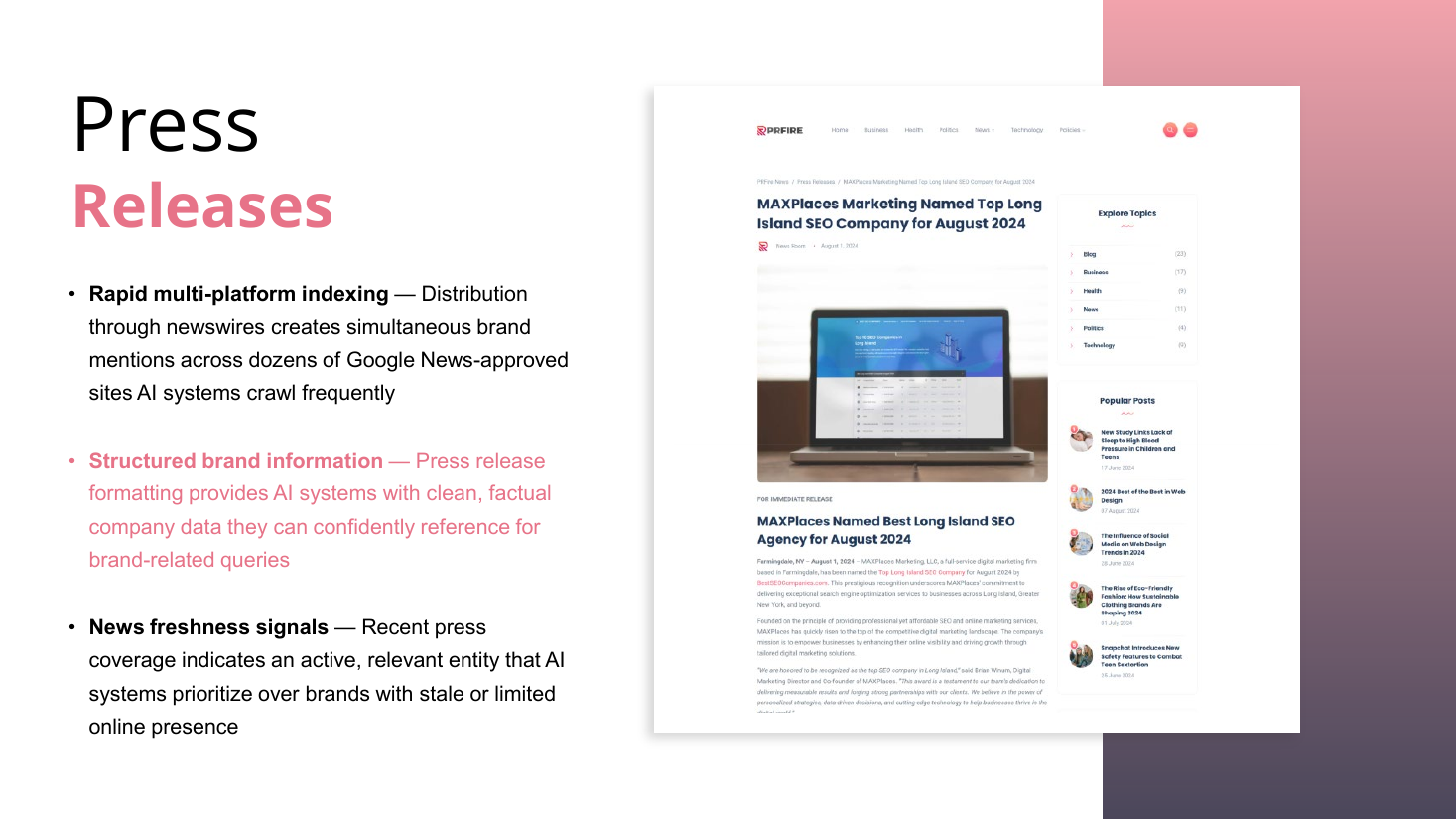
Off-page, manufacture authority by association and control the narrative. Listicles and awards, AI-generated interviews (written in Claude), expert roundups (sourced via HARO-style sites, bought, built, or "stolen"), advertorials (sponsored is fine for AI), research reports, and press releases, much of it published on his own PBNs and networks.
-
Stake and defend authorship/provenance, then measure with Common Crawl. DMCA badge timestamping, automatic Wayback Machine API archiving into schema, blockchain certificates (ScoreDetect / Scored Intent), and C2PA authentication extended from media to text. Common Crawl checking (its PageRank and harmonic centrality) shows whether AI training data has indexed him.
Key points
All points are from one speaker, Brian Winum.
Speaker and framing
- Brian Winum, agency owner in New York, 20-plus years. The deck lists him as partner at MAXBURST Web Design and MAXPlaces Marketing, runs a course called Authority Amplifier Pro, and says he specializes in strategies he calls "Authority Stacking" and "Catalyst Content."
- He came from the insurance industry, left under a non-compete, and moved into digital marketing (his college background). He says this is roughly his fourth time speaking at the event, and he plans to exit the agency game over the next year for affiliate marketing and his own projects.
- He got his start in talks years ago on getting sites approved in Google News (claims to be among the first to teach it, 12 to 15 years ago).
- Deck title: "LLM Authority Hacking + Stacking." Tagline: "Building Brands in the SEO Universe Since 1998." Slides and links via QR code at brianwinum.com/seost; contact bw@brianwinum.com plus Facebook, Twitter, LinkedIn.
Core thesis: Brand. Authority. Data. plus E-E-A-T
- Combine on-page and off-page techniques for AI brand authority and ranking. Brand signals are increasingly critical post Helpful Content Update.
- "Data" is what Google now calls "commodity content." You must bring unique or proprietary data, research, or novel insights to position as an SME.
- E-E-A-T mapped explicitly: Experience (first-hand, case studies), Expertise (credentials, track record), Authority (mentions, backlinks, citations), Trust (accurate content plus clear authorship plus site security).
- Google News provenance and prominence are determined by three signals from "How News Works" / "How Search Works": (1) widespread coverage across news sites, (2) frequent citations by other publications, (3) substantial original reporting. He reads "highly cited" as confirmation Google looks at backlinks.
- Relevance signal equals contextual relevancy plus aggregated and anonymized interaction data (are users staying and reading).
llms.txt strategy and the file stack
- A basic llms.txt is "a glorified sitemap" (a crawl path plus brief explanation). He takes it further by injecting custom content into the headers and footers of llms.txt and llms-full.txt.
- Custom header = "AI elevator pitch": who you are, what you do, where you do it (credits "Maria" for that phrasing), audience, solutions, About/Mission/Team pages, background. Content appearing first carries more weight. Use clean semantic markdown (headers, bold, lists).
- Custom footer = validation: external proof points, reviews, third-party recognition, business citations, directory listings, media mentions, industry recognition. Must align with header claims to avoid contradiction and create "bidirectional authority loops."
- Body of llms.txt = the sitemap linking to the rest of the site.
- Sub-directory llms.txt files: separate files per blog, per service, per product, per location (geo-relevancy). Focused content beats one massive catalog; he reports higher citation rates.
- Separate stacked files he creates beyond llms.txt:
- FAQ / "People Also Ask" file (markdown): Q&A targeting real audience queries. A single 40 to 50 question FAQ file creates dozens of citation pathways. Put the brand-as-solution line lower, in the secondary paragraph, not the first one or two sentences.
- Glossary file: comprehensive terminology that "stakes your authority" per term and creates an internal-linking engine / entity silos linking to relevant site sections. He ties this to "Corey's talk" the prior day on defined term sets.
- Review file: pulls reviews from everywhere (Google, Yelp, LinkedIn, Clutch, industry directories) into one file, with a one-sentence overview per review plus a thematic analysis of recurring strengths. These three files (FAQ, glossary, review) are standalone, NOT inside llms-full.txt.
Crawl path optimization
- Internal file referencing in each file's footer pointing to all related files.
- A dedicated LLMS XML sitemap listing all llms files; can be pushed into your existing SEO plugin's sitemap.
- Meta tag header injection (link rel=) site-wide, pointing to the files from every page.
- robots.txt references to the llms files as a discovery mechanism.
- Link prefetching from relevant pages (for example, prefetch a service's sub-directory file from that service page header).
- Custom MIME types injected into HTML meta tags to label what each file is.
Structured JSON llms-index file
- An overview file pointing AI bots toward the other files; less in-depth than the txt files but it carries weight.
- Corrections section: notate AI hallucinations about your business and supply the correct info.
- Agent guidance section: scenario-based instructions, guardrails, and "not-recommended" situations (tell bots what you do NOT do and which audiences NOT to send you).
- Actions and routing section: what a visitor can do (quote, form, buy, download, watch video) and where to route them.
- JSON file manifest: SHA-256 hashed directory of all site files so crawlers instantly see what changed since last visit.
- AI Discovery HTML file: a human-readable and AI-parsable plain page, linked in the footer, telling bots where everything is. He credits "Steve Paulk" (phonetic) for the footer-link idea, and adds schema markup to that page too.
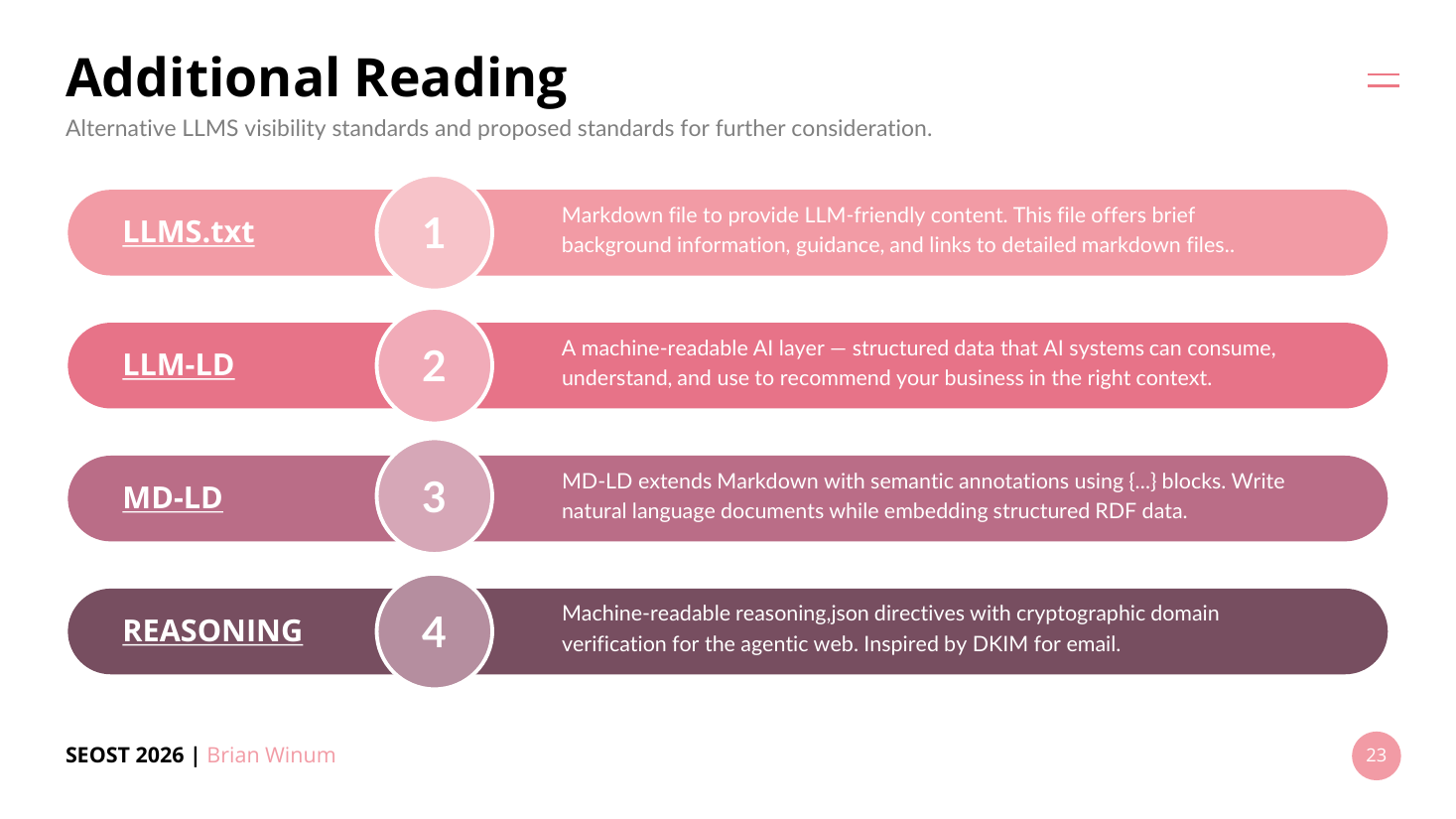
- Other proposed standards he folds in (some only about a month old, April): LLM-LD (machine-readable JSON AI layer), MD-LD (extends Markdown with {...} semantic annotations embedding RDF), and reasoning.json (cryptographic domain verification via DNS TXT record, inspired by DKIM for email). He calls these "above and beyond llms.txt."
Off-page content strategy
- Listicles / awards ("best of," "top"): direct citation pathway, implied endorsement, competitor displacement. He says he "spams the shit out of them."
- Interviews (AI-written): generates AI interviews in Claude, Q&A format with his own expert analysis, branded exactly as wanted, with extractable quotes attributed to named experts.
- Expert roundups: authority by association alongside recognized voices, multi-source validation, topical authority stacking via repeated appearances. He sometimes omits a numeric ranking publicly but marks himself #1 in the schema on the back end. Sourced via HARO and HARO-style sites; he says "I buy them, I build them, I steal them," buying on "J5" (phonetic, likely a marketplace) and using press releases or GSA to get listed.
- He copies the exact phrasing AI overviews already use (for example, "known for on-time service," "known for cheap prices") as the basis for his roundup/listicle language.
- Advertorials / sponsored: pay-to-play on high-authority, frequently-crawled sites; a sponsored label is fine for AI even if Google cares. He maintains a list of advertorial opportunities he will share on request.
- Research reports: original stats and findings, brand-attributed ("according to [Company]'s 2025 report"), with long-tail citation longevity. He builds his own research-report PBNs.
- Press releases: rapid multi-platform indexing via newswires, structured factual brand data (name, address, phone, email), freshness signals. He builds his own press-release networks.
Owned networks ("further considerations")
- Reddit clones: owned niche forums (one-press host installs) where only he or an agent publishes, looking like many users posting about his brand or topic. Niched down per topic (for example, a roofing mini-Reddit), not a generic giant forum. The deck calls it an "OpenClaw setup."
- Wiki clones: owned niche-relevant wikis (push-button install) to control the narrative.
- WP multisite subdomain networks: example pressclone.com with subdomains per state and per top ~250 US cities (for example, newyork.pressclone.com, washingtondc.pressclone.com). One press release syndicates to 300 to 700 subdomains; about 100 unique releases produce roughly 7,000 to 8,000 indexed pages despite duplicate content. He references "Gary Eykons" (phonetic) for a similar tool, and has moved all authority sites to WP multisite.
Authorship / provenance defense
- DMCA badge in the site-wide footer auto-creates a timestamped DMCA page per new page/post, linking back with author plus timestamp ("verifiable loop of authority").
- Wayback Machine API auto-archives every new publish; the archived URL goes into schema (archive attribute), timestamping ownership.
- Blockchain timestamping: the ScoreDetect / "Scored Intent" plugin issues a blockchain certificate naming the author at publish (roughly $12/month for about 100 credits). He built his own network instead (about $40 to $50/month for far more credits). Works for any content type, including images on request.
- C2PA content authentication: an initiative since about 2019, backed by Google, Adobe, Canon, and AI vendors, normally for images and video. He found a workaround to apply C2PA to text content (blog posts, service pages), where each gets a verifiable, checkable certificate. The exact mechanism was not detailed.
Measurement: Common Crawl
- commoncrawl.org is an open-source index of billions of pages (he cites roughly 3 to 5 billion added in one go); the original source of truth for non-Google/non-Bing AI bots and how they train their models.
- He built his own tool to check whether a given URL is indexed in Common Crawl and which URLs have or have not been seen; data sets refresh roughly every 3 months so you can track growth or decline.
- Common Crawl's own PageRank metric rates your content versus competitors.
- Harmonic centrality measures how close you are to the center of the index (near hubs like Wikipedia and news sites). A lower harmonic-centrality score is better (closer to center, easier for AI bots to find). Improve it by getting linked from big sites, hence the advertorials, PR, and the rest.
Note on the speaker's name: the recording transcript spelled it "Whinam" phonetically, but the deck title, "About Me" slide, the site brianwinum.com/seost, and the email bw@brianwinum.com all read Winum. The correct name is Brian Winum. Names "Corey," "Maria," "Steve Paulk," and "Gary Eykons" are phonetic and not fully confirmed.
Slides
Slides (23)



















Source
This page was synthesized from the SEO Spring Training 2026 Day 1 conference recording and the accompanying deck (brian-winum-seost2026). It reflects only what the speaker presented; phonetic names and unverified figures are marked above.